
CVPR2023:ARCTIC A Dataset for Dexterous Bimanual Hand-Object Manipulation 阅读笔记
[toc]
论文研究背景、动机与主要贡献
研究背景及动机
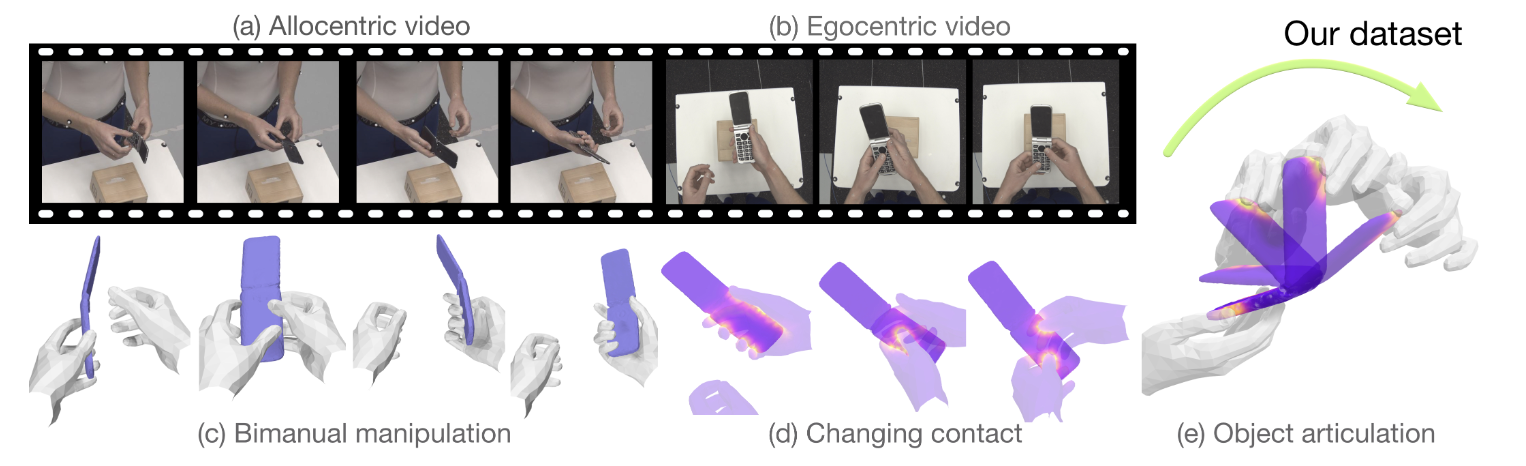
人类本能地理解,无生命的物体不会自己移动,但状态的变化通常是由人类操纵引起的(例如,打开一本书)。对于机器来说,情况还不是这样。在某种程度上,这是因为没有数据集具有真实的3D注释,用于研究手部和关节物体的物理一致和同步运动。
论文介绍了一个名为ARCTIC的数据集,旨在研究灵巧的双手物体操作。
1. 人-物交互数据集的需求: 随着计算机视觉和机器学习技术的发展,对于能够理解和模拟人与物体之间复杂交互的数据集的需求日益增加。尤其是双手与物体之间的交互,这种交互在日常生活中非常常见,但在现有的数据集中很少被深入研究。
2. 3D手和物体重建的挑战: 从单目视频中重建3D手和物体的运动是一个具有挑战性的任务。现有的方法和数据集往往只关注手或物体的单独重建,而忽略了它们之间的交互。
主要贡献
1. ARCTIC数据集的推出:
数据内容:ARCTIC数据集包含了手操作关节物体的视频,这些视频不仅捕捉了双手与物体之间的复杂交互,还提供了精确的3D手和物体网格以及详细的接触信息。这些信息对于理解和模拟双手与物体之间的交互至关重要。
2. 提出两个新颖的任务:
- 一致性运动重建:这是一个旨在从单目视频中重建手和物体的3D运动的任务。与传统的3D重建任务不同,这个任务强调了手和物体之间交互的一致性,确保重建的运动与实际观察到的视频中的运动相匹配。
- 交互场估计:这是一个涉及从图像中估计手和物体之间的相对距离的任务。这个任务的目标是理解手和物体之间的空间关系,从而更好地模拟它们之间的交互。
3. 对相关工作的讨论:
- 论文还讨论了与人-物数据集和3D手和物体重建相关的工作。这部分内容不仅为读者提供了背景知识,还强调了ARCTIC相对于其他数据集和方法的独特贡献。
一致性运动重建
问题描述
给定一个视频,目标是为每一帧重建主体的双手和一个关节物体的3D运动。重点是要求重建的手-物体网格在物体的关节和操作过程中具有时间上一致的手-物体接触和运动。
参数模型:
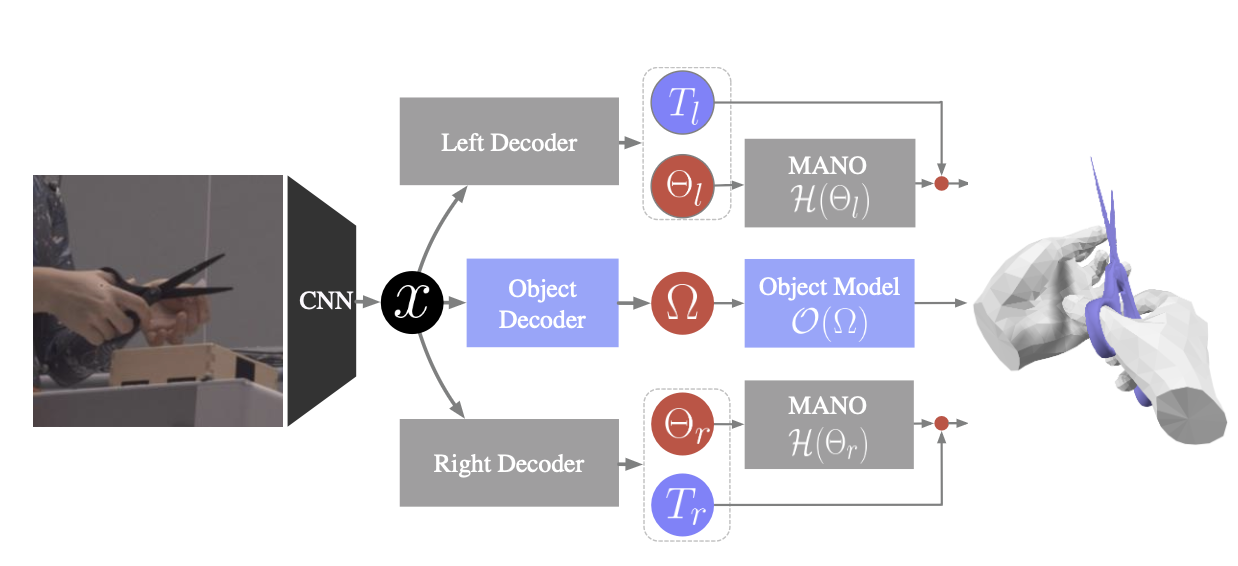
- 使用 l 、 r 和 o 分别表示左手、右手和物体。
- 对于手部,使用MANO模型来表示手部姿势和形状,由 $\Theta = \{\theta, \beta\}$ 表示,其中 $ \theta$ 是姿势参数, $\beta$ 是形状参数。MANO模型将 $\Theta$ 映射到一个形状和姿势的3D网格 $H(\theta, \beta)$ 。它由48维的姿态(具有全局方向)和10维的形状的参数组成。3维 J 的3D关节位置使用预先训练的线性回归器W获得。MANO模型将手映射到一个形状和姿态的778x3的三维网格H。
- 对于每个物体对象,我们使用扫描对象网格、估计的旋转轴和估计的标记顶点对应构建一个三维模型O。物体姿态7维Ω,包括关节的1D旋转(弧度)1维ω,和6D物体刚性姿态,即其旋转3维R0,和平移3维T0。以铰接的对象姿态Ω作为输入,并输出一个姿态的三维网格O(Ω)(维度为Vx3),其中V表示对象的顶点数。对象解码器预测对象旋转、相机参数和对象清晰度。
评价指标:
接触和相对位置
接触偏差 (CDev):
对于一帧,假设有 C 对接触的手-物体顶点 $\{(h_i, o_i)\}^C_{i=1} $,以及相应的预测 $\{(\hat{h}_i, \hat{o}_i)\}^C_{i=1} $。CDev定义为 $\hat{h}_i $ 和 $\hat{o}_i$ 之间的平均距离越小越好
Mean Relative-Root Position Error (MRRPE):
- 定义:用于衡手或物体之间的相对根部平移。
- 计算:对于两个实体a和b,计算GT的根部位置与预测的根部位置之间的L2距离。
$MRRPE_{a \to b} = || (J_{a0} - J_{b0}) - (\hat{J}_{a0} - \hat{J}_{b0}) ||_2$
其中,$J_{a0} 和 J_{b0}$分别是实体a和b的GT的根部位置,$\hat{J}_{a0}和 \hat{J}_{b0} $ 分别是实体a和b的预测的根部位置。
运动
运动偏差 (MDev):
给定一个手和物体的地面真实序列,我们使用 $ht_i$ 和 $ot_j$ 分别表示手的顶点 i 和物体的顶点 j 。当两个手-物体顶点 $ht_i$ 和 $ot_j$ 在一个窗口内稳定接触时,它们应该在连续帧中朝同一方向移动。为了衡量这一点,我们定义了预测的手-物体序列 $\hat{h}$ 和 $\hat{o}$ 的元组 $(i, j, m, n)$ 的运动偏差为:$MDev = \frac{1}{n-m} \sum^n_{t=m+1} ||\delta\hat{h}_i - \delta\hat{o}_j||$ 其中,$\delta\hat{h}_i = \hat{h}_i - \hat{h}_{i-1} $ 和 $\delta\hat{o}_j = \hat{o}_j - \hat{o}_{j-1}$。
加速度误差 (ACC):
为了衡量重建的平滑性,我们报告加速度误差,计算为地面真实和预测顶点序列之间的加速度差异。
手
- Mean Per-Joint Position Error (MPJPE):
- 计算:对于每只手,计算21个预测关节与GT关节之间的L2距离,然后减去其根部位置。
- $MPJPE = \frac{1}{N} \sum_{i=1}^{N} || p_i - \hat{p}_i ||_2 $
其中,( $p_i$ ) 是GT的第i个关节位置,( $\hat{p}_i$ ) 是预测的第i个关节位置,N是关节的数量(例如,对于手部,N=21)。
物体
Average Articulation Error (AAE):
- 计算:对于每一帧,计算预测的关节角度与GT关节角度之间的绝对误差,然后取所有帧的平均值。
- $ AAE = \frac{1}{T} \sum_{t=1}^{T} | \omega_t - \hat{\omega}_t |$
其中,( $\omega_t $) 是在帧t的地面真实的关节角度,( $\hat{\omega}_t$ ) 是在帧t的预测的关节角度,T是帧的数量。
Success Rate:
- 定义:为了衡量物体重建的质量,使用一个与物体大小无关的成功率指标。
- 计算:计算预测的物体顶点与GT顶点之间的L2误差小于物体直径5%的顶点的百分比。
- $\text{Success Rate} = \frac{1}{V_o} \sum_{i=1}^{V_o} 1(|| o_i - \hat{o}_i ||_2 < 0.05D) \times 100\%$
其中,( $o_i$ ) 是地面真实的第i个物体顶点,( $\hat{o}i$ ) 是预测的第i个物体顶点,( $V_o$ ) 是物体顶点的数量,D是物体的直径,1(·)是指示函数,当括号内的条件为真时值为1,否则为0。
多样性评价指标human motion generation
模型 ArcticNet
两个模型:单帧模型(ArcticNet- sf)、循环架构模型(ArcticNet- lstm)
使用在ImageNet上预训练的ResNet-50主干。模型使用Adam优化器进行训练,学习率为1e−5。为了提高可见度,在物体中心的正方形区域周围裁剪每个图像,并将图像大小调整为224 × 224。数据增强:旋转(±30◦),缩放(±25%)和颜色抖动(±40%)。
ArcticNet- sf

相机参数:焦距、旋转和平移。用于将3D模型投影到2D图像上,从而可以与实际的2D图像进行比较和对齐。
物体七维度姿态怎么来?
1D关节旋转+3维旋转R+3维平移T
其中关节旋转对应附录Table 4 物体分支中的16行 (这个预测的好像不是物体清晰度),3维旋转R对应14行。
在附录3.1 Camera model中介绍了使用相机参数(s, tx, ty ),得到手和物体的3维平移T的公式。
对象解码器预测的东西有啥用?
对象解码器(object decoder)应该是指附录Table 4的Object Branch,可以得到物体的七个维度。
The 3D joint locations J是什么
“The 3D joint locationsJ = WH ∈ IRJ×3 are obtained using a pre-trained linear regressor W .”
结合上下文,H是指指将Θ = {θ, β}输入到MANO后的3D网格H(Θ, β)∈IR778×3
手的三维J(The 3D joint locations)就是H左乘一个W(线性回归量),应该就是我们最后想得到的手的三维空间位置。
相互作用场估计
问题描述

InterField
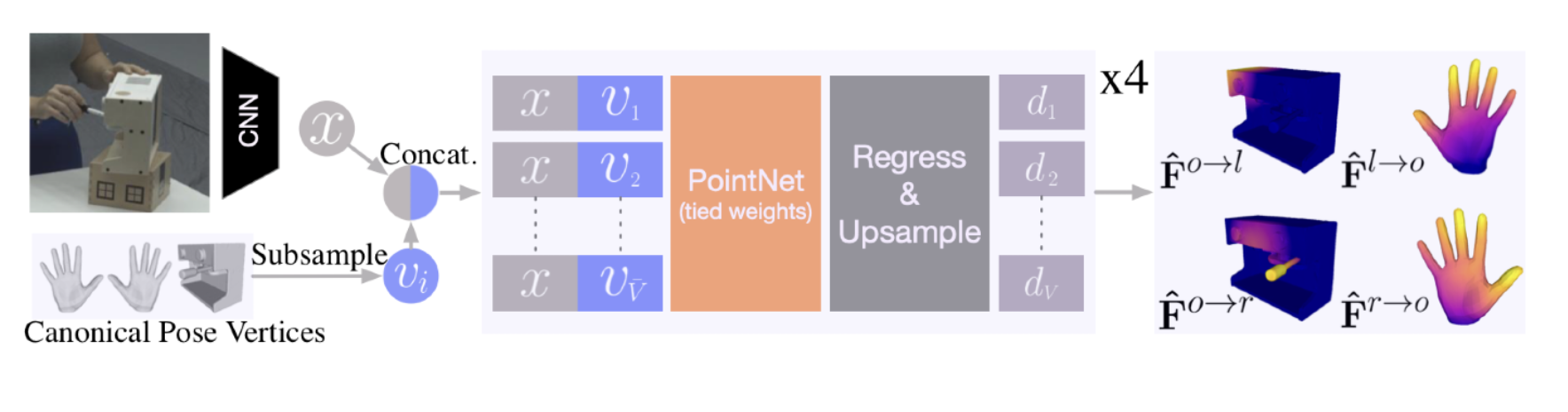
首先通过CNN主干提取图像特征X。接下来,我们将X连接到左手(l)的每个次采样顶点,以获得所有pi= [x; vi ] ,其中vi表示次采样顶点的数量。所有的点pi都被输入一个PointNet,然后是一个估计距离的回归头。预测的距离被上采样到全网格(778)。
为了提高效率,我们对PointNet使用下采样顶点到较低维度,并使用上采样进行回归。其余的交互场是通过相同的网络估计与一个共享参数的CNN和pointNet,但不同的头。
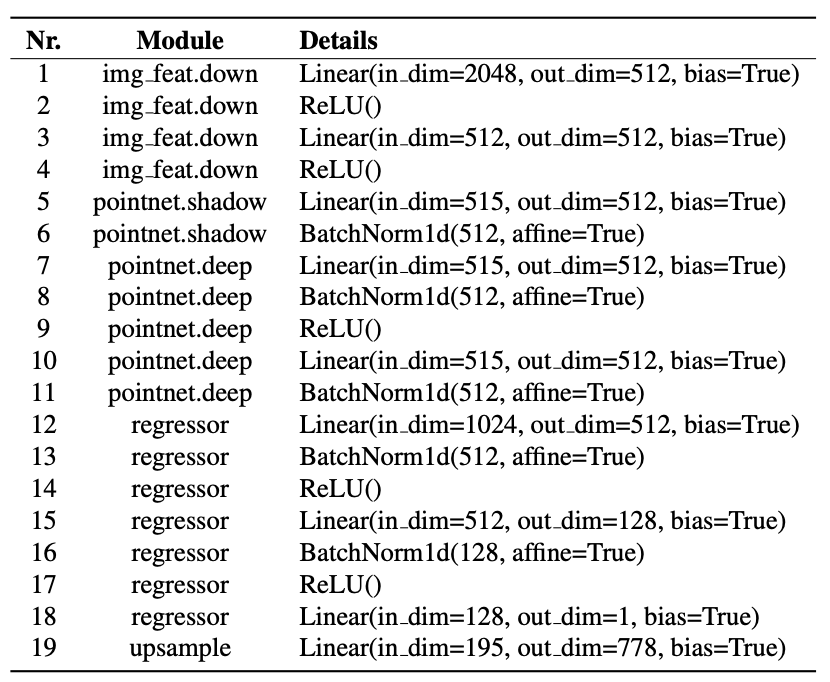
- 图像特征提取:从输入图像中,我们使用图像骨干网络获得一个2048维的图像特征向量。
- 特征降维:该向量通过一个多层感知机(MLP)并被投影到较低的维度以提高计算效率(Line 1-4)。
- 点云构建:我们使用手的子采样顶点,并将每个顶点的3D位置与512维的图像特征向量连接,得到一个具有515维的点云。这个点云通过PointNet骨干网络,得到一个512维的潜在点云(Line 5-11)。
- 点云特征提取:515维的输入点云通过一系列层来产生较低级别的点特征(Line 5-6)。点特征进一步通过Line 7-11进行处理。然后,我们沿着特征维度连接浅层(Line 6的输出)和深层(Line 11的输出)的点云,得到一个1024维的点云。
- 距离预测:一个回归器将每个点(1024维)映射到一个用于距离预测的单一标量(Line 12-18)。最后,我们将子采样的距离上采样到完整的手部网格(Line 19)。
- 其他实体的预测:我们以相同的方式预测左手和物体的交互场。所有实体共享相同的图像和PointNet骨干网络。
Discussions and Limitations
- 已知的物体模型:与现有方法类似,我们的基线方法假设物体模型是已知的。我们认为未知物体的3D形状估计是一个正交问题,该领域正在取得进展。现在我们已经展示了为这样的物体推断手-物体交互的可行性,未来的工作应该将我们的方法与3D关节物体推断结合起来。
- 玩具物体:我们的部分物体是玩具,它们的尺寸不是真实比例,缺乏真实物体的视觉复杂性。但ARCTIC的目标是研究手与物体之间的物理动力学。
- 捕捉接触的SMPL-X:我们使用SMPLX/MANO作为人的表示,但人的几何形状在接触时并没有捕捉到皮肤的变形。虽然一个可变形的人体/手模型对于捕捉真实的接触是理想的,但开发这样的模型不是ARCTIC的目标。
- RGB图像中的手部标记:我们使用光学标记捕捉来提供准确的手和物体姿态,这可能会引入标签噪声。但我们的手部标记非常小(半径1.5mm),在图像调整大小用于输入时几乎看不见。
- 我们的物体的自由度:我们构建的ARCTIC物体有1个自由度。这是因为为人类交互设计的许多物品通常只有一个旋转轴,因为它们容易生产且直观易操作。因此,ARCTIC中的物体代表了家庭和企业中常见的广泛物体类别。
- 人类主题数据的批准:主题数据是在获得书面、事先、知情的同意后收集的,数据收集已经过大学伦理委员会的审查。







