
ACL2023:Vision Language Pre-training by Contrastive Learning with Cross-Modal Similarity Regulation
论文研究背景、动机与主要贡献
研究背景及动机
这篇论文的研究背景聚焦视觉语言预训练(Vision Language Pretraining,VLP)。VLP通过结合处理视觉和语言信息来学习跨模态的表示。最近,基于大规模预训练的视觉语言模型在不少任务中都取得了很好的效果,如图像标注、视觉问答和视觉推理等。传统的VLP方法通常依赖对比学习,这种方法通过最大化正样本,并最小化负样本之间的相似性来学习跨模态表示。然而这种方法难以效地处理“假负样本(False Negatives)”。如图1所示,图像和文本之间存在多对多对应关系,如I4和I5被标记为负样本,但它们其实也符合或部分符合“A big bird in the tree”的描述。这些假阴性样本的存在显然会对模型效果产生负面影响。
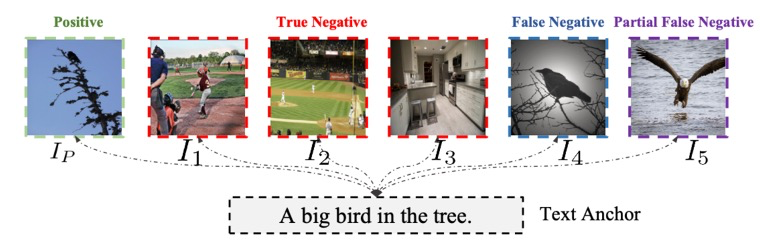
图1 文本和图像存在多对多的关系
论文的主要动机就是解决这个问题。作者从互信息(Mutual Information,MI)优化的角度,通过调节跨模态的相似性来优化对比学习。通过研究过去的InfoNCE loss是怎样最大化MI的,作者发现,优化InfoNCE相当于最大化正样本和锚点(当前的正样本文本)之间的MI-P与负样本和锚点之间的MI-N的差值的下界。也就是说即使一些负样本在语义上与锚点匹配,MI-N也会被最小化。
受此启发,作者为每个负样本引入了一个对比权重,这个权重与负样本与锚点的跨模态相似性成反比,并随着训练逐步变化。通过这种方式,可以防止MI-N被最小化,False Negatives的对比效果会被减弱,从而减少它们对学习表示的负面影响。
主要贡献
\1) 作者从MI优化的角度,推导出了InfoNCE loss的MI下界的一般形式。发现了假阴性和锚点之间的MI会被错误最小化的问题。
\2) 基于这个推导。作者提出了一种新的跨模态对比学习方法SRCL(Similarity Regulated Contrastive Learning) 通过引入一个新的对比权重,使得模型能够根据样本之间的跨模态相似性动态地调整对比权重,从而有效地解决了上述问题。
\3) 在各种下游任务上,如Zero-shot跨模态检索和视觉问答,论文的方法都明显优于现有SOTA模型。作者还通过实验证明了其在处理大规模数据时的优势。
论文问题描述或定义
在VLP中,模型通常会接收到一对图像和文本作为输入,然后通过对比学习的方式进行训练。目标是让模型能够将相似的图像和文本对靠近,将不相似的图像和文本对远离。但这种方法存在假阴性问题,那些实际上是相似的图像和文本对,可能被模型错误地认为是不相似的。因此作者从MI优化的角度,通过调节跨模态的相似性来优化对比学习。MI是一种度量两个随机变量之间相互依赖程度的方法,可用来评估两个随机变量之间的信息共享量。
作者推导出了InfoNCE Loss的MI下界的更一般形式:

该式假设负样本和锚点是独立的,但当存在不可忽略的假阴性时,负样本和锚点可能并不独立。当存在不可忽略的假阴性,重新推导可得出更一般的结论。等式左边的第一项是锚点和正样本之间的MI,第二项是锚点和负样本之间的MI期望。这表明优化InfoNCE等价于最大化前者和后者之间差的下界。

论文提出的新思路、新理论、或新方法
模型的pipeline如下图所示。通过阅读论文附录可知,ImageEncoder是使用CLIP中预训练的ImageEncoder(ViT-B/16)进行初始化的,TextEncoder和Crossmodal fusion network中使用的是6层的Transformer。
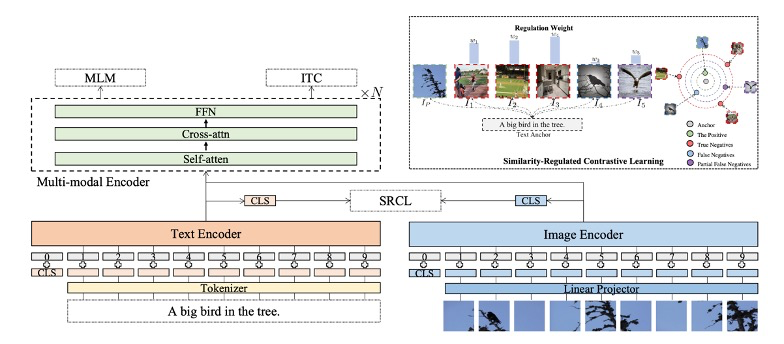

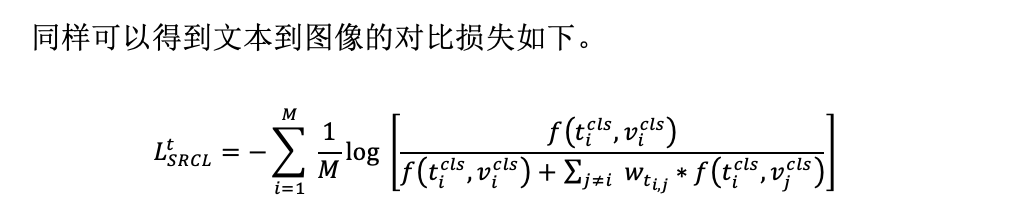
那么如何计算对比学习中负样本的调节权值呢?核心思想是调节权重与锚点和负样本之间的语义相似性成反比。因此先要计算语义相似性。虽然VLP模型可以用来衡量跨模态的语义相似性,但在早期的训练阶段的VLP效果并不好。
因此作者先训练了另一个模型Hβ,与VLP模型Sγ具有相同的结构,使用InfoNCE Loss训练,用于在早期预阶段估计图像文本对的语义相似性。将Sγ和Hβ计算得出的相似度加权平均就得到了最终锚点和负样本之间的语义相似度。
加权系数的计算规则是:训练开始时,Sγ的权重设为0,Hβ的权重设为1,随着周期增加,Sγ权重逐渐增加,Hβ的权重逐渐减小。

上述方法通过计算语义相似性,然后根据相似性计算对比权重,实现了对负样本的有效调节。这样做是为了根据负样本与锚点的语义相似性动态调整负样本的权重,从而使对比学习更加有效。
论文方法的理论分析或实验评估方法与效果
实验部分,基于ALBEF框架在Conceptual Captions、SBU Captions、MSCOCO、Visual Genome四个数据集进行预训练。
文章在四个下游任务上进行了定量评估,包括:图像文本检索,Zero-shot图像文本检索,视觉问答和用于视觉推理的自然语言(natural language for visual reasoning)。图像文本检索方面,在MSCOCO和Flickr30K数据集上进行TR和IR的实验。微调过程中同时优化了SRCL loss和ITM loss。视觉问题回答方面,文章将其当做答案生成任务,并使用了受限的近似词生成模型。视觉推理的自然语言方面,该任务要求预测一个句子是否描述了一对图像,其实就是一个二分类任务。Zero-shot图像文本检索是在Flickr30K进行实验的。在这四个下游任务上的结果,都说明了将SRCL引入ALBEF可以显著提高性能。
此外文章还探讨了“False Negatives”与“Hard Negatives”。这里说的Hard Negatives是指那些被错误分类成正样本的负样本,它和False Negatives边界的模糊的。这里存在一个悖论:一方面我们希望减少False Negatives的影响,这些False Negatives中包含了一定的Hard Negatives,另一方面大家都在尝试通过增加Hard Negatives来提高学习效果。
作者设计实验探究了这个问题,他们调整了False Negatives(包含一定的Hard Negatives)的比例。发现当移除部分False Negatives时,模型的性能会有所提升,但如果移除过多,模型的性能又会下降。这也印证了论文方法的优越性,通过跨模态相似性调节能更好地平衡False Negatives带来的好处和坏处,从而提高模型的性能。此外作者还通过实验证明了其在处理大规模数据时的优势。
对Zero-shot文本图像检索结果进行定性分析的如下图所示。文本为“a woman with blond hair is sitting in a booth with a drink working on her laptop”,可以看到ALBEF过于关注“a woman with blond hair”,但忽视了关键信息“working on her laptop”。 这表明文章的方法能全面地捕捉相似性。并且结果排名能反映出从完全对齐到部分对齐的趋势。

总结
本文主要贡献有两个,一是从MI优化的角度,推导出了InfoNCE loss的MI下界的一般形式,发现了假阴性和锚点之间的MI会被错误最小化的问题;二是基于这个推导,提出了一种新的跨模态对比学习方法SRCL。作者通过大量的实验说明了该方法的有效性,并发现平衡False Negatives对于学习跨模态表示的重要性。
论文的主要优点是:1、理论分析与相关推导较为详细,这为理解和使用本文的方法提供了有力的理论支持。2、SRCL的具体实现很简单,但是非常有效。也比较容易地添加到其他的基于对比学习模型中。
但也有一些不足:虽然论文的方法在他们的实验中表现优秀,但都是基于一个Baseline: ALBEF来验证的。如果能将其应用到其他的VLP中,实验结果会更有说服力。此外关于False Negatives与Hard Negatives的讨论不够深入,值得进一步的探究。
论文带给我的启示是做研究可以从问题的“痛点”下手。在跨模态对比学习中,False Negatives会对模型的性能产生负面影响,如何有效地处理False Negatives是一个重要的问题。为此作者提出了相似调节对比学习SRCL,通过引入一个新的对比权重,使得模型能够根据样本之间的跨模态相似性动态地调整对比权重,从而有效地解决了这个问题。此外,严谨的数学和理论推导也是非常重要的,它能帮助我们更好的发现和理解这些“痛点”,也能为论文提供有力的理论支撑。
对于后续的研究,我认为可以从以下几个方面探索。
1、尝试将这种方法应用到其他的VLP,或其他的跨模态任务中,比如音频和文本的对比学习,看看是否能得到类似的结果。
2、本文为每个负样本引入了一个对比权重,通过优化对比权重可以更好地处理假负样本的问题。可以设计出一种新的对比权重,来更好地解决这个问题,比如参考信息瓶颈对比学习的思想。
3、可以尝试针对False Negatives做一些数据预处理(比如mask掉一些特定的词汇);也可以尝试结合生成式模型,来生成更多的负样本,从而提高模型的鲁棒性;以及对multi-modal encoder的架构进行改进等等。







