
CVPR2023(Award Candidate)Ego-Body Pose Estimation via Ego-Head Pose Estimation 阅读笔记
[toc]
论文研究背景、动机与主要贡献
在以自我为中心的视频中,人体的大部分关节通常不可见,这为问题带来了重大挑战。尽管从以自我为中心的视角看不到身体关节,但环境变化的视觉信息为推断头部如何移动提供了强烈的信号。这项工作,使用头部姿势作为中间表示来连接以自我为中心的视频和全身动作。
EgoEgo首先集成了SLAM和学习方法来估计准确的头部运动。随后,利用估计的头部姿势作为输入,Ego利用条件扩散生成多个似是而非的全身运动。
最大的好处在于:方法的分解消除了从成对的以自我为中心的视频和人体姿势中学习的需求,从而能够结合大规模单模态数据集(例如,只有以自我为中心的视频或 3D 人体姿势的数据集)进行学习。
我们的工作做出了四个主要贡献:
- 我们提出了一个分解范式,EgoEgo,将从以自我为中心的视频中的运动估计问题分解为两个阶段:自我头部姿势估计,以及基于头部姿势的自我身体姿势估计。
- 我们为自我头部姿势估计开发了一种混合方法,结合了单目SLAM的结果和学习。
- 我们提出了一个条件扩散模型,根据头部姿势生成全身姿势。
- 我们为不同的方法提供了一个大规模的合成数据集,并展示了我们的方法在很大的范围内优于基线。
模型
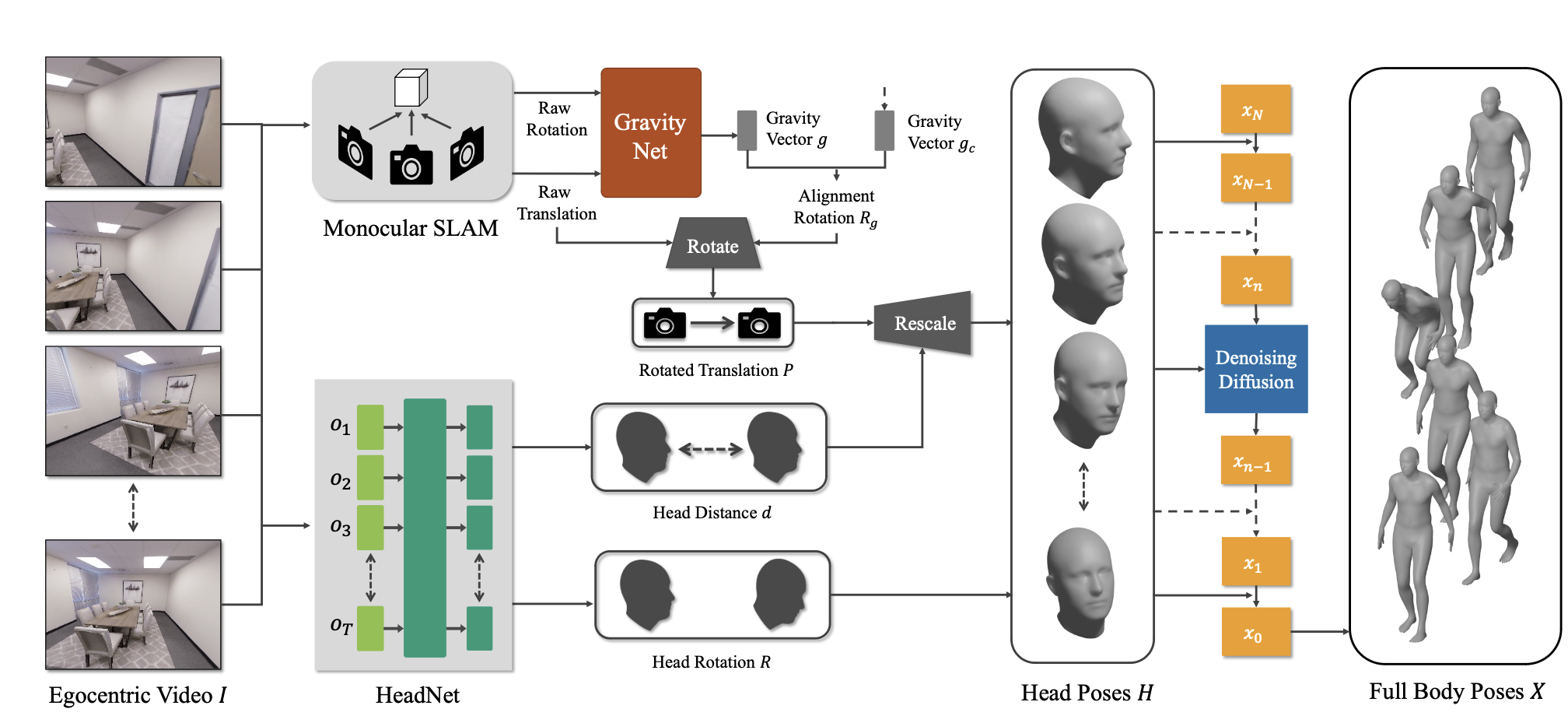
头部姿势估计
重力方向估计(GravityNet):
- 由于单目SLAM系统不能准确地估计重力方向,所以需要一个专门的网络来估计它。
- GravityNet使用一个基于变压器的模型来估计重力方向。它首先使用预训练的ResNet-18从以自我为中心的视频中提取特征,然后通过变压器模型进行处理。
- 为了模拟从单目SLAM得到的头部姿势的分布,GravityNet在训练时对AMASS数据集中的头部姿势应用了随机的缩放和旋转。
- 基于GravityNet的预测,计算旋转矩阵Rg以对齐预测的重力方向g和正确的重力方向gc。
头部姿势估计(HeadNet):
- HeadNet的目标是从以自我为中心的视频中预测头部的距离和旋转。
- 与GravityNet相似,HeadNet也使用预训练的ResNet-18从视频中提取特征,并使用基于变压器的模型进行处理。
- HeadNet预测两个关键输出:头部之间的距离差异(d1, d2, … dT)和头部的角速度(ω1, … ωT)。
- 通过集成预测的角速度,可以生成相应的旋转R1, …, RT。
- 在推断过程中,假设给定了第一个头部方向,并集成预测的头部角速度来估计后续的头部方向。
与SLAM的结合:
- 直接应用最先进的单目SLAM方法会产生不满意的结果,因为未知的重力方向和估计空间与真实3D世界之间的缩放差异。
- 为了解决这些问题,提出了一种混合解决方案,结合了SLAM和学习的基于变压器的模型,从以自我为中心的视频中实现更为准确的头部运动估计。
从头部姿势估计全身姿势
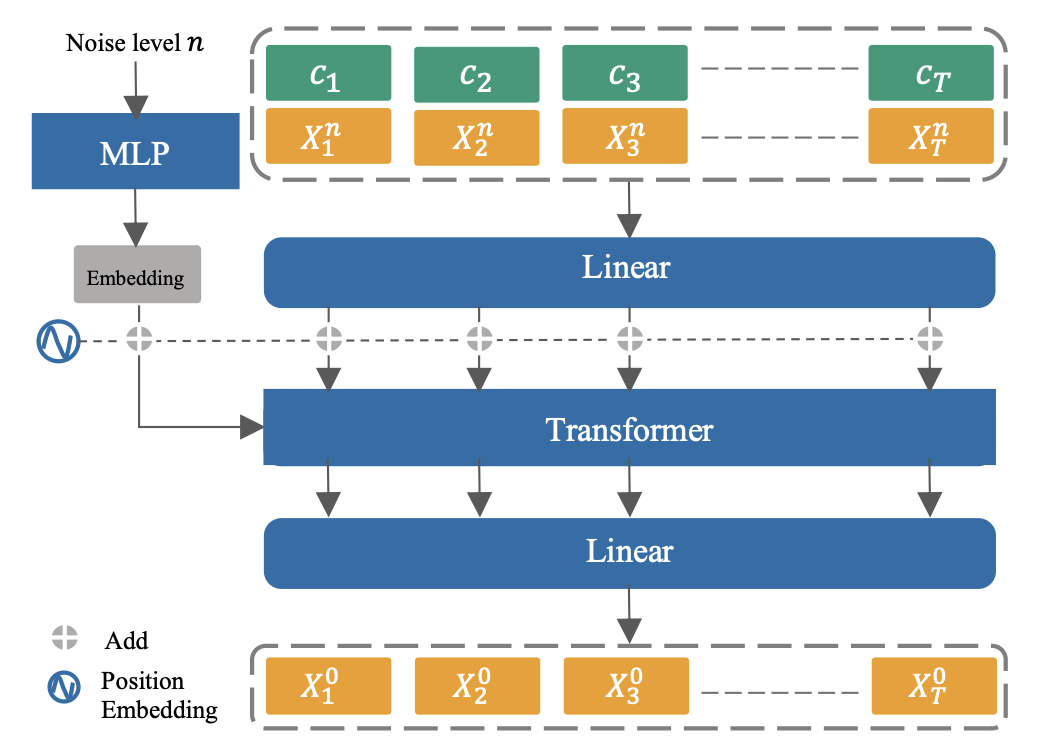
在时间t的身体姿势 $X_t \in \mathbb{R}^D$ ,使用的SMPL模型
$X^n$ 来表示噪声级别为n的身体姿势序列 $X^n_{1}, X^n_{2}, \ldots, X^n_{T}$。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 魔法使いの秘密基地!
相关推荐





评论
最新文章


