
万字解读~~~大规模预训练模型在视觉理解中的应用——以CLIP为例
The application of large-scale pre-trained models in visual understanding—the case of CLIP
本篇博客将以CLIP为例,介绍大规模预训练模型在视觉理解上的应用
我会先介绍问题的背景,也就是什么是大规模预训练模型。然后以Open AI的CLIP模型为例,介绍其在视频检索,图像生成,目标检测,三个方向上的应用。最后进行总结
Background of Pre-trained mode
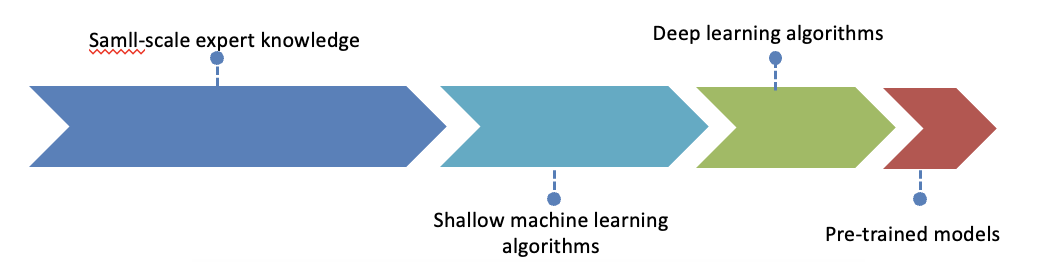
视觉理解的历史其实是非常悠久的。有人提出 它是经历了 四个技术变迁,四个范式的转变。早期是基于这种小规模的专家系统后来呢是基于浅层的机器学习,像svm,决策树。这往往需要人工取提取特征,然后经过机器学习的方法 把这些特征组合起来。
但是后来随着深度学习的出现, 这种特征的人工选取 已经不再重要了,深度学习能够摆脱复杂的特征工程,机器可以自动的完成。
近几年,随着数据集的增大和算力的提升,出现了预训练的方法。通过海量的数据,先预先学习一个模型参数,然后再以用于不同的任务。
具体来说,传统的机器学习和深度学习方法呢,是假设有大量未标注的数据,从这里面选取出来一些,做数据标注,形成一个目标任务的数据集,再针对这个数据集进行训练,最终得到我们的模型。
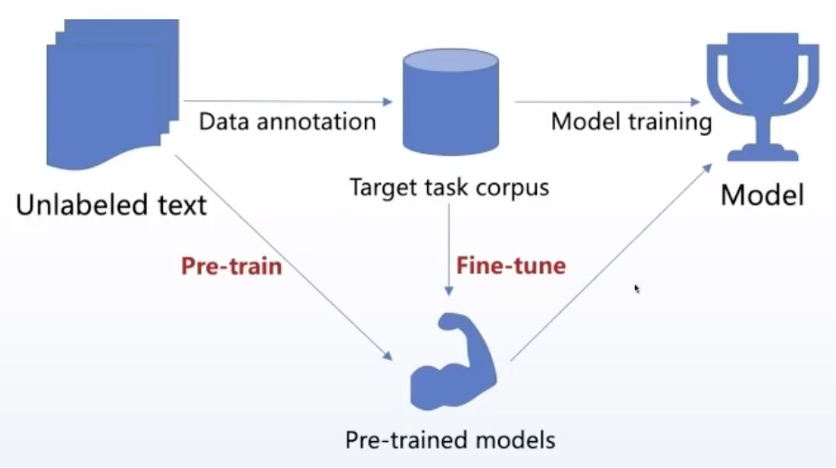
互联网的发展带来大量的数据,特别是未标注的数据,那么有没有办法从这些未标注的数据里面进行预训练,学习一个模型,然后在下游任务的时候,在具体的任务上进行精调,这样得到一个更好的下游任务的模型。这就是预训练模型解决问题的方法。
当然,如今的预训练模型越来越朝着few-shot learning,甚至是zero-shot learning的方向发展。
随着预训练模型规模的不断扩大,一些大语言模型,出现了“涌现”的能力,有非常好的效果,比如chatGPT,这也使得“大规模预训练模型”受到了学术界和社会广泛的关注和期待。
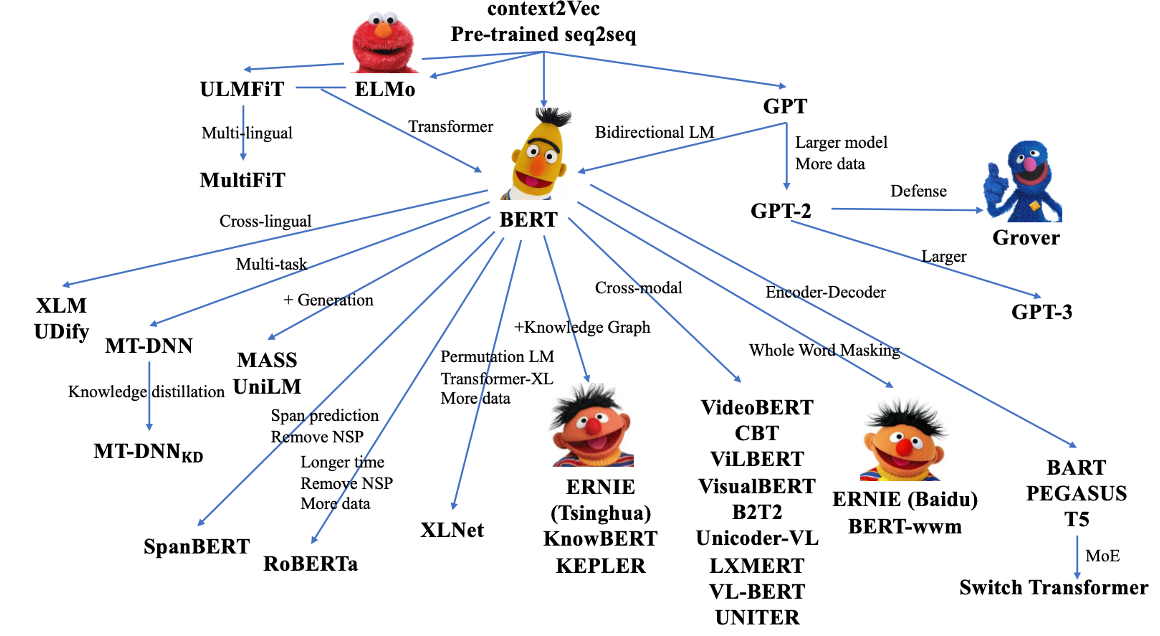
这是一些代表性的预训练模型,最早的一批预训练模型是出现在NLP领域,比如说BERT和GPT。
后来CV和多模态领域涌现出了一系列的工作,像是CLIP、Dalle2、包括上个月发布的segment anything,都取得了非常好的效果
CLIP
Zero-Shot Learning
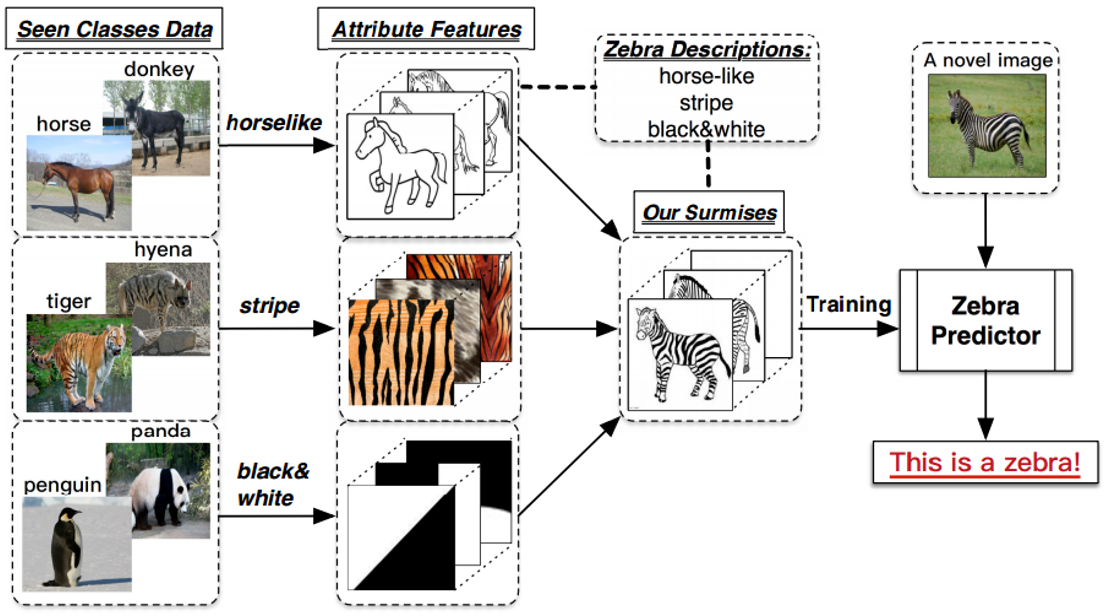
在讲CLIP之前,我想先简单介绍一下Zero-Shot Learning这个概念
如图所示,最左边一列是训练集图片,最右边一列的斑马,是测试集的图片,并且训练集类别和测试集类别不重合,也就是说,测试集图片 就是模型没有见过的图片,也就是Zero-Shot。
zero-shot learning要做的事情,就是从训练集图片中学习出一些属性
比如这里学到的horselike、stripe(straɪp)和black&white,然后将这些属性相结合,得到融合特征。
这个融合特征,刚好和测试集的 斑马的特征 相匹配,最终得到预测结果为斑马。
这个过程就是zero-shot learning。
Background of CLIP
CLIP是OpenAi在2021年2月发布的,用于匹配图像和文本的预训练模型,在很多任务表现上达到了当时的SOTA。最出色的一点是CLIP在不使用imagenet训练集的情况下,也就是不使用128万张图片的任何一张进行训练的情况下,他直接zero-shot进行推理,就可以和之前有监督训练好的resnet50达到同样的效果。
CLIP模型主要解决了下面两个问题
第一是模型训练需要用大量的标注数据,获取这些标签需要大量的人力和时间;同时呢数据被标注后,会被标签限制
第二点是,过去的模型,泛化能力很差,迁移到新的训练任务也比较困难
为了解决这两个问题,作者团队首先收集了4亿图片文本对作为训练样本。
之所以要构建新的数据集,是因为以往有的数据集要么规模太小,相是COCO,要么数据标注质量太差,如YFCC100Milion。
Approach
Pre-train
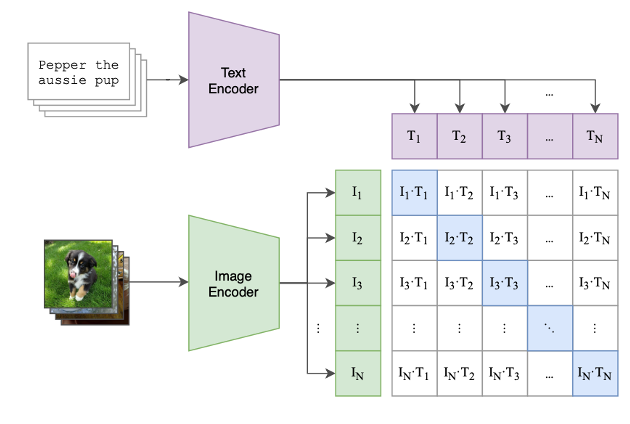
首先是预训练的过程,使用的是对比学习的方法。
数据是图片和它对应的文本描述对,文本描述输入进TextEncoder,提取到文本特征T,图片由ImageEncoder得到图片特征I。
有N个图片和文本描述,所以能提取到N个文本特征T1到TN,还有N个图片特征I1到IN。
将他们的特征进行组合,填进这个特征表里面,可以看到对角线上是配对的,在对比学习中称为正样本,其他地方都是负样本。也就是说就有N个正样本和N方减N个负样本。然后用他们进行对比学习的训练
关于网络模型的选择,TextEncoder使用的是Transformer,ImageEncoder它是尝试了8个模型,从resnet到ViT,实验发现ImageEncoder的性能是与网络复杂度成正相关的,所以他这里使用了ViT的large14

这里展示了训练的伪代码
先是将文本和图片分别输入对应的Encoder,提取特征。
再将它通过一个投射层,也就是全连接层,目的是将单模态特征投射到多模态中,再进行L2的正则化。
然后将这两个特征进行余弦相似度计算,最后求出Loss
那么为什么要使用nlp的信号,也就是文本,来训练视觉模型呢?这有一下三点好处
第一是无需标注,可以节省大量的人力和时间
第二点是因为监督信号是一段文本,相比固定的标签,自由度大了很多
第三点是学到的特征是多模态的,易于做zero-shot transfer。
Why use contrastive learning
作者解释了采用对比学习的原因
由于数据集有四个亿的图片文本对,所以训练的效率是非常重要的
如果使用预测模型来完成,也就是逐字逐句预测出文本的话,这个任务很难,效率也是非常低的,因为一个图片可能会对应很多种文本描述,同一个文本也对应着很多种场景。
所以作者选择使用对比学习的方法判断文本和图片是否为一个配对,训练效率就有很大提升。
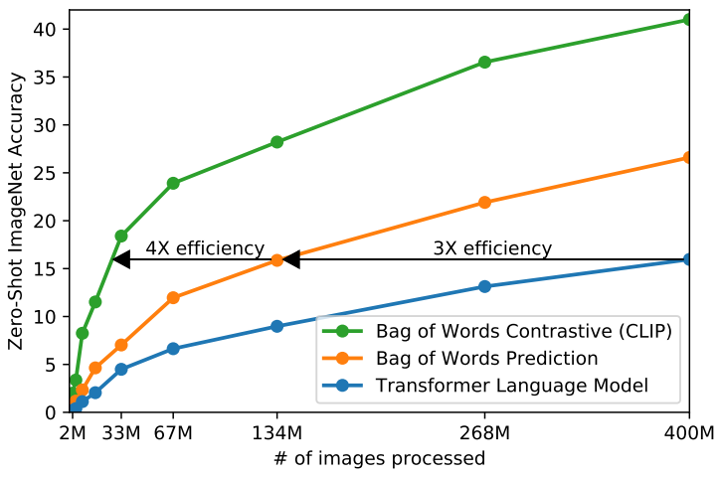
为此作者设计了一些实验,图中蓝线是使用Transformer直接预测文本,橙线是使用Bag of words,也就是提取一些embidding之后再训练,这样效率就提升了三倍。
最后就是CLIP的对比学习方法,可以看到训练效率进一步提高了四倍
这也就说明了基于对比学习的方法是非常高效的
Zero-shot Prediction
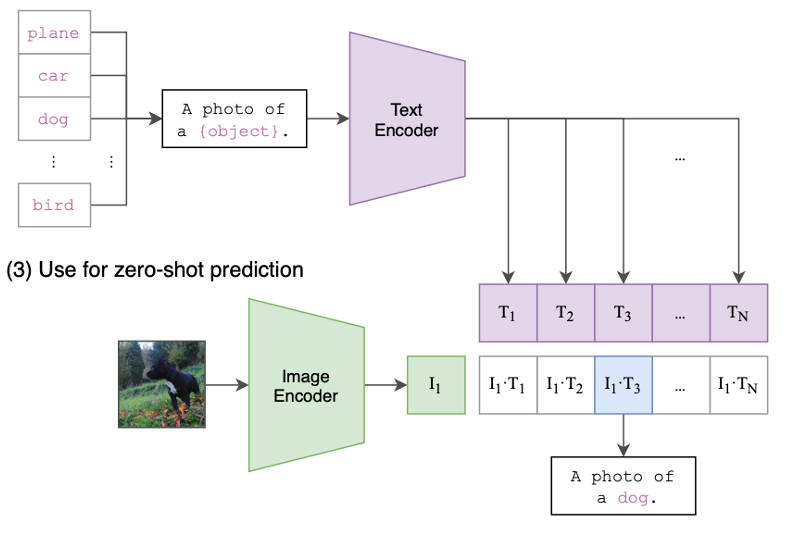
接下来介绍CLIP的zero-shot预测部分
CLIP通过引入NLP领域的Prompt template方法,将类别以填空的形式构造成一句文本描述句子,送进TextEncoder得到每个类别的特征向量。
在做推理的时候,对于任意一张输入的照片,将它输入ImageEncoder提取特征后和所有的文本特征计算余弦相似度,找到哪个文本特征和图像特征最相似,把对应的文本挑出来,这就完成了分类任务。
因为文本是可以任意设计的,CLIP在使用的时候可以对任意类别进行分类。同样,图片也可以是任何数据集中的图片。这为CLIP进行zero-shot transfer提供了基础,也是clip相比以往的模型最强大的地方。
Why Prompt?
第一是因为单词有多义性,如果只用一个单词并不好,比如bus可以表示公交车,也可以表示总线
第二是因为在训练的时候就是用的句子,如果在推理的时候变成了一个单词,效果会有下降
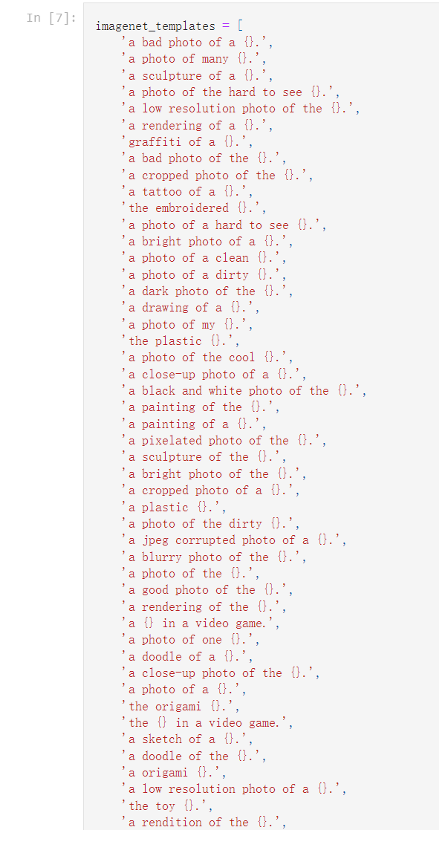
论文中是使用了80个提示模板
值得一提的是,在对特定的数据集,使用特定的提示模板会得到更好的效果。比如对食物的数据集,使用a kind of food进行提示,会很有用;在做 OCR 任务的时候,在想要识别的文字上打上双引号,模型也能理解这样一个意思。
总之,使用Prompt方法,将label放进对应语境的句子中,可以有效提高label的表现力
Experiments
Analysis of Zero-shot
作者花了十几页的篇幅讲解他们的实验,这里我选取了一些进行展示
在实验之前,首介绍一下zero-shot transfer的动机
预训练模型,主要是研究特征学习的能力,模型的目标是学习泛化性能好的特征,但是应用到下游任务中时,仍然需要有标签数据进行微调
那么能不能训练一个模型,在应用到下游任务时无需微调呢。CLIP借助文本引导,就能很灵活的去做zero-shot transfer。
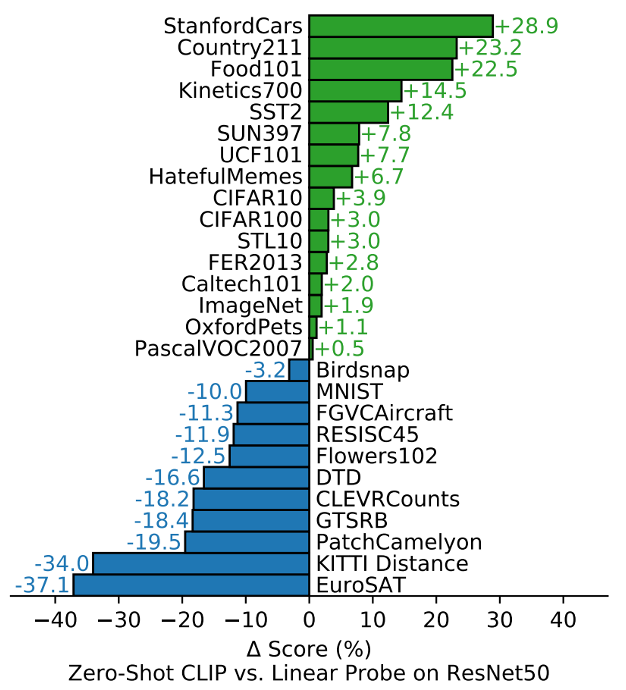
这张图展示了实验结果,作者在27个数据集上进行了实验
比较的双方,一个是做zero-shot的CLIP,另外一个是在预训练好的ResNet50上对每个数据集做微调
绿色的部分表示CLIP模型在这些数据集上表现更好,蓝色部分表示CLIP表现更差
可以看到在大多数数据集上zero-shot的CLIP都超过了有监督训练好的resnet50,证实了zero-shot transfer是可以广泛应用的
可以看出,对于一些普通的对物体进行分类的数据集来说,比如车子、食物这样的,CLIP一般都表现的比较好。 但是对于一些更难的数据集,比如CLEVR Counts这种给图片中的物体计数,在完全不给标签信息的情况下,对CLIP来说还是太难了。
对于特别难的任务,比如给肿瘤做分类,对于我们人来说,在不学习相关知识的情况下都是非常难的。因此在这些任务上做zero-shot transfer可能并不合理。
Analysis of Few-shot
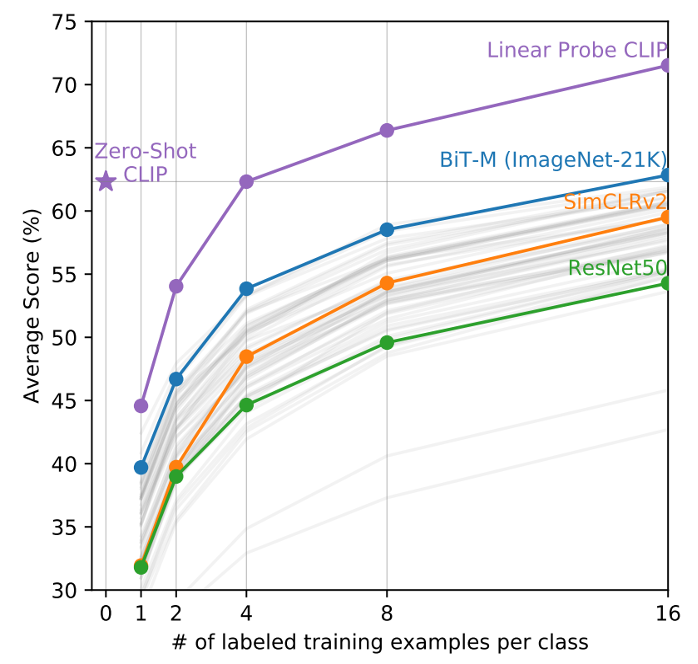
于是作者研究了CLIP在few-shot上的表现,使用的是Linear Probe,也就是冻住backbone,只训练分类头。
图片的横坐标是指 数据集中每个类别里用了多少训练样本,0就表示是zero-shot
纵坐标是在这些数据集上的平均准确度
可以看到在few-shot上面CLIP相比其他模型都要强不少
有意思的一点是CLIP在four-shot之前,few-shot的能力是比不上自己的zero-shot的
Analysis of Generalizability

然后是泛化性测试
文章中使用ResNet-101为baseline,用CLIP,和它在不同的数据集上来比泛化性能。当输入数据有out of distribution时,也就是偏离分布的话,一般网络模型的性能都会变差。可以发现resnet的分数是逐渐降低的,特别是在最后面这两个,素描画和对抗样本数据集上表现非常差。而clip是比较稳定的,说明这种使用自然语言信号训练的模型,它的泛化能力,和对图像的理解能力是很强的。
Comparison to Human Performance
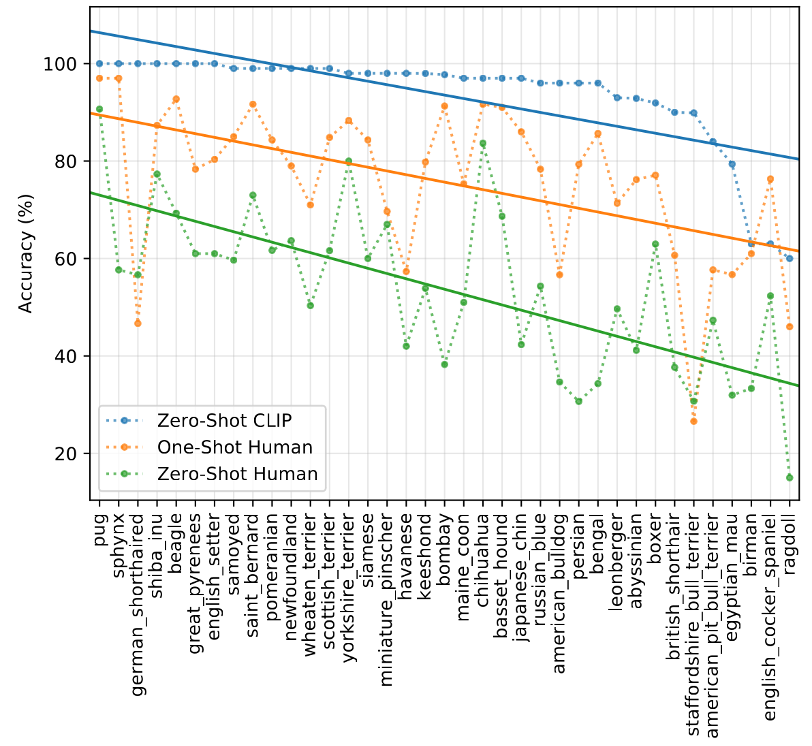
作者还将CLIP的表现与人类进行对比,得到了一个有意思的结果
作者找了一群人,让他们去看宠物数据集中的测试图片。
图中横坐标表示宠物的种类,纵坐标表示准确率,绿色的线表示zero-shot的人类;橙色的线表示one-shot的人类,意思就是提前给人们 每个种类 看一张图片,告诉他这个种类的宠物长什么样;蓝色的线表示zero-shot的CLIP。
可以发现,对于人来说简单的类,对于CLIP来说也很简单;对于人来说难的种类,对于CLIP来说也很难,这有可能和现实中宠物种类的分布有关系。人类对于常见的宠物种类很熟悉,在CLIP的数据集中应该也出现过很多,因此准确率都很高。
CLIP Related Works
CLIP4Clip

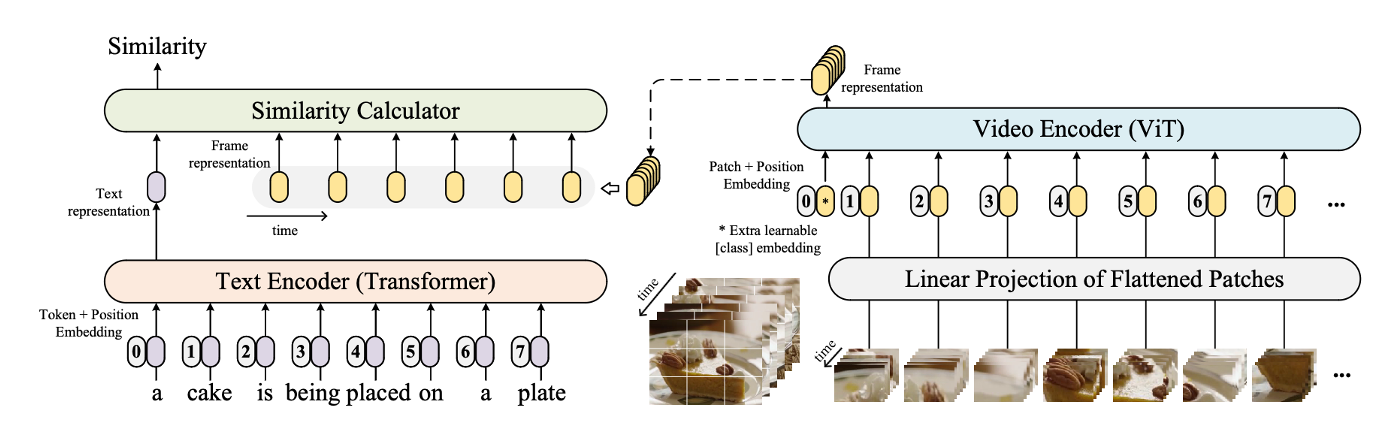
CLIP4Clip这篇文章是一篇实证研究的论文,内容是比较简单的
CLIP模型非常适合做检索类任务,因为他就是在算图像和文本的相似性。所以很自然能想到把它扩展到视频领域,去做文本和视频的匹配。
如图左边所示,文本方面和CLIP一样,直接将文本输encoder得到cls token。
在视频这边,因为视频相比图像多了一个时间的维度,它是由连续的帧组成的,每一帧通过encoder都会得到一个cls token,它们是有时序性的。
那么如何将一个文本特征和若干个图像特征 做相似性计算呢,这就是这篇文章所探讨的内容

文章尝试了三种方法
第一种方式是最简单的。它是直接将每个图像特征取平均,得到一个特征,那就和CLIP一样了。这种方法非常简单,不需要引入任何可学习的参数。但也有一个很大的局限性,它并没有考虑到图像的时序性,比如有两个打篮球的视频,第一个是人在抛球,另一个是一个人在接球。因为只是取平均,没有考虑时序特征,所以得到的结果可能是相似的,无法区分是在抛球还是在接球。
我们的目的是要将这若干个时序的特征融合成一个,很自然能想到使用LSTM这种时间序列模型。第二类方法也是这样做的。目前更常用的是使用Teansformer,在加上position embedding后也能够对时序进行建模。
在第二类方式中,是先把若干的图像特征融合成一个,再将这个融合的特征和文本特征做对比。而第三种方法,是让文本特征在最开始就参与到融合中来。具体来说,就是将文本的特征和若干图像特征一起,加上位置编码后,输入进Teansformer。这相当于把文本特征当做一个cls token。最后把这个token经过一个线性层,就得到了相似度。
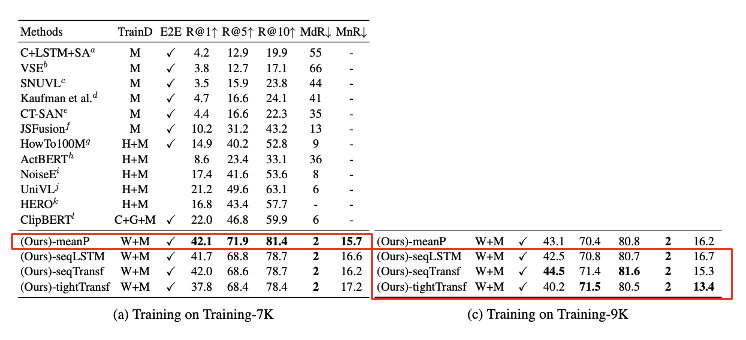
这是和之前的其他方法对比结果,可以看到不管是哪种特征融合方法,只要是使用CLIP,相比以往的方法都能取得很大的提升。
然后是这几种特征融合方法的对比,左边的表格是在7000个视频上去微调的,右边的表格是在9000个视频上去微调的。
通过左边的表格可以看到,在数据较小的情况下,直接取平均的方法是最好的,也就是说在少量数据进行微调的情况下,这种最简单的无参数的学习方式反而是最好的。
只有当微调数据量增大后,后面那几种融合方式才能取得更好的效果。
CLIPasso

这篇CLIPasso获得了SIGGRAPH 2022的最佳论文奖。顾名思义,CLIPasso是CLIP和毕加索两个单词的结合,是将CLIP用于素描简笔画的生成。如图所示,它是想把给定的图片,一步步变成简笔画的形式,并保留图片语义和结构上的信息。
为什么作者选要结合CLIP来解决这一问题呢,主要原因有两点:
第一点是为了保持语义感知

这张图是毕加索的名画,一头公牛。
这种简笔画,需要理解理解,和对高级概念的先验知识。对人类艺术家来说是一种挑战,对机器来说更是如此,必须保证语义上和结构上都能被识别才行。
CLIP使用的是 图片和文本 的对比学习方式,它对物体是特别敏感的,能够很好地抓取物体的语义信息。作者通过实验观察到,不管图片风格如何,CLIP都能把物体的视觉特征抽取的很好,也就是非常的稳健
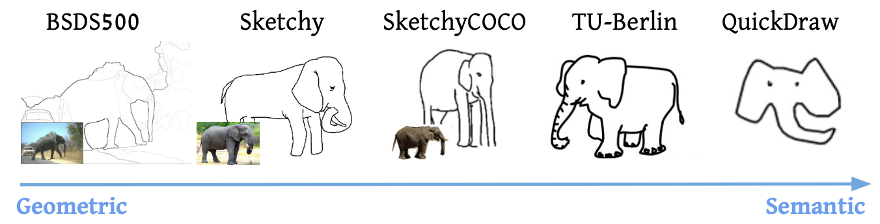
第二点是为了摆脱有监督训练的数据集。之前的一些相关工作,都是收集特定的素描数据集进行训练。有什么数据集,就学出什么模型,抽象程度是固定的,所以最后生成的风格非常受限,这就违背了初衷。
此外,素描数据集很少,学到的种类就不够丰富。比如说SketchyCOCO就只有9个类别,都是常见的动物。训练完的模型碰到这些类别之外的物体,效果并不好,还需要收集相应的数据进行微调。
CLIP有出色的zero-shot transfer的能力,完全不用在下游任务上进行任何的微调
基于这两点原因,就有了CLIPasso
来看Clipasso的方法部分
首先定义一下任务。我们的任务就是在一张白纸上,画一些贝塞尔曲线。这些贝塞尔曲线是随机初始化的,通过一系列的训练迭代,最后构成我们想要的简笔画。
贝塞尔曲线 是通过一系列平面上的点 控制的曲线,模型通过更改这些点的位置,来控制贝塞尔曲线的形状。具体怎样用这些点控制贝兹曲线,这就是图形学的事情,这里就不多讨论了。
下面具体介绍每个模块是怎么完成的。
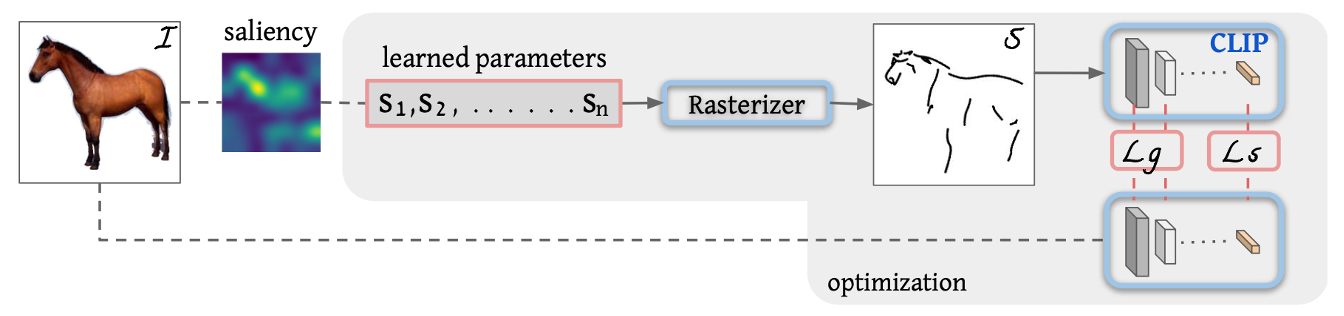
假如现在定义了一些笔画,也就是这里的 S1 到 Sn ,将这些笔画输入进一个光栅化器,它就能将这些笔画画在画布上,变成我们能看到的图像。
这一块都是图形学已有的工作,并不是文章的贡献,所以我们重点介绍其他部分。
在这里,作者巧妙的使用CLIP设计了两个Loss函数。
生成的简笔画有两个要求,第一个是语义和原图保持一致,比如马还是马、牛还是牛。第二个是结构上和原图保持一致,不能生成了马,但是马从站着变成趴着。在 CLIPasso 中,这两个要求分别由两个损失函数来保证,也就是语义损失Ls 和 几何距离损失Lg。
先来看语义损失 Ls,相当于把CLIP当成Teacher来蒸馏这个模型。对于原始图像和后面生成的简笔画图像,如果他们描述的是同一个物体,那么经过CLIP编码后的特征都是同一语义,所以要让这两个特征尽可能的接近。
只保留语义信息是不够的,还需要有几何上的一致。
于是作者又设计了几何距离损失Lg。因为在模型的前几层,学习到的还是相对低级的,几何纹理上的信息,而非高层语义信息,这些是对几何位置比较敏感的。因此,可以约束这些浅层的特征,来保证原图和简笔画的轮廓更相似。

此外,作者还发现,如果完全随机初始化贝塞尔曲线的话,模型会很不稳定,有的初始化后不管怎么训练效果都不好。所以需要一种更加稳定的初始化方式。
作者使用了注意力机制 来解决初始化的问题。将图像输入进一个预训练好的ViT模型,对多头自注意力取加权平均得到“显著图”,再在这个显著图上进行踩点,来初始化贝塞尔曲线。这样模型的效果就稳定了许多。
最后来看一下实验结果

之前的方法只能对数据集中有的类别生成简笔画,而很难生成数据集以外的。借助CLIP的zero-shot能力,CLIPasso对不常见的物体也能生成简笔画,这是这个模型最突出的优势。
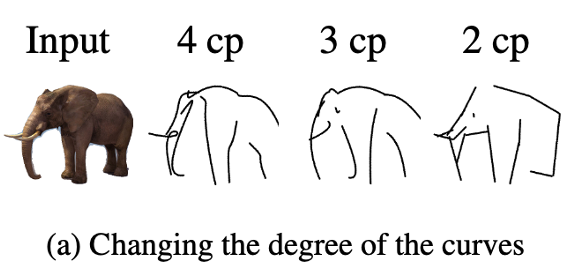
此外,通过调整初始的贝塞尔曲线的数量,可以实现不同的抽象程度
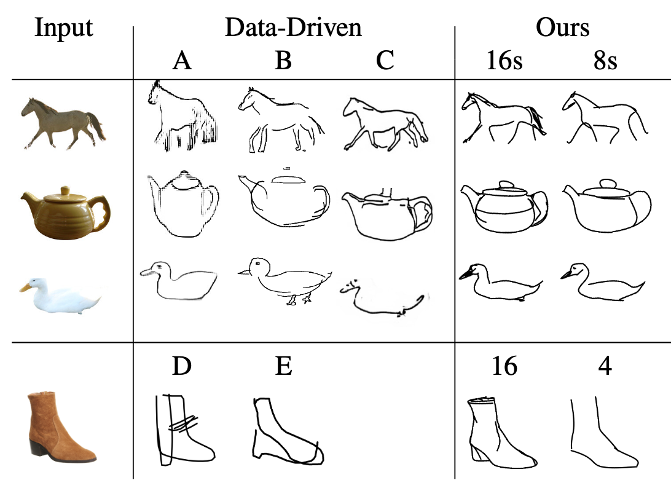
和其他方法进行对比,可以看到CLIPasso的优势很明显
ViLD

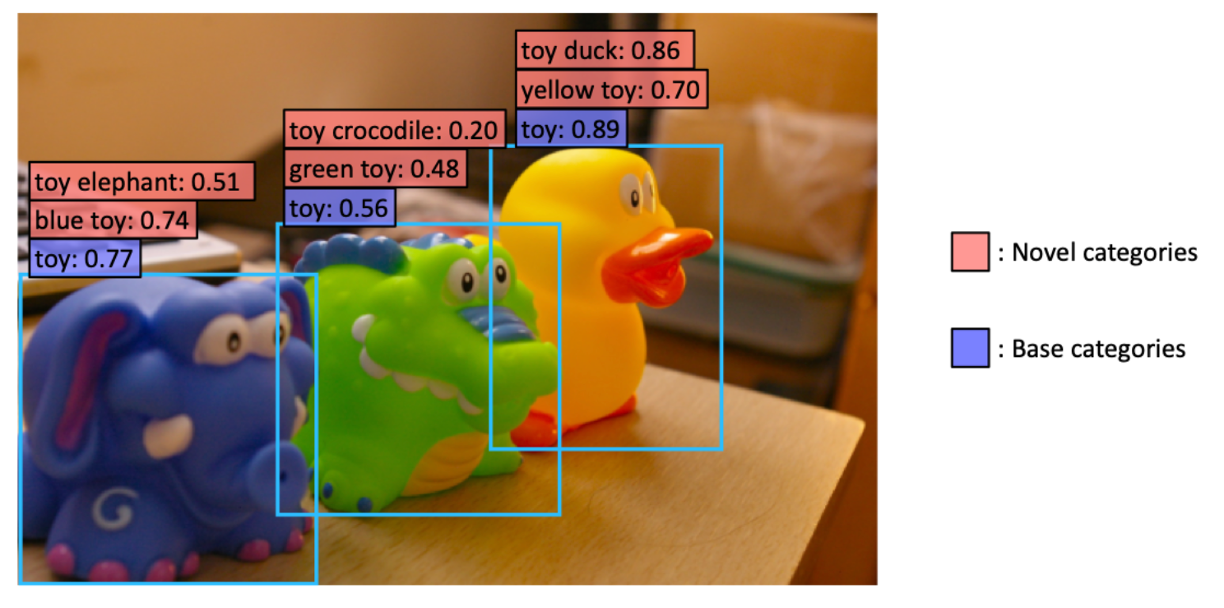
ViLD的出现是为了解决这样一个问题
现在的目标检测数据集标注的类别都很有限,比如图中蓝色框中,都被识别为了玩具,toy。
但存在更细致的类别,就像红色框总所写的这样,比如这里的黄鸭子,绿鳄鱼。
作者希望在现有数据集的基础之上,不去进行额外地标注像是黄鸭子、绿鳄鱼这些。还能让模型具有能够检测这些物体新的类别的能力。
简单来说,ViLD 想要做到的事情是:在训练时只需要训练基础类,然后通过知识蒸馏从 CLIP 模型中学习,从而在推理时 能够检测到任意的新的物体类别
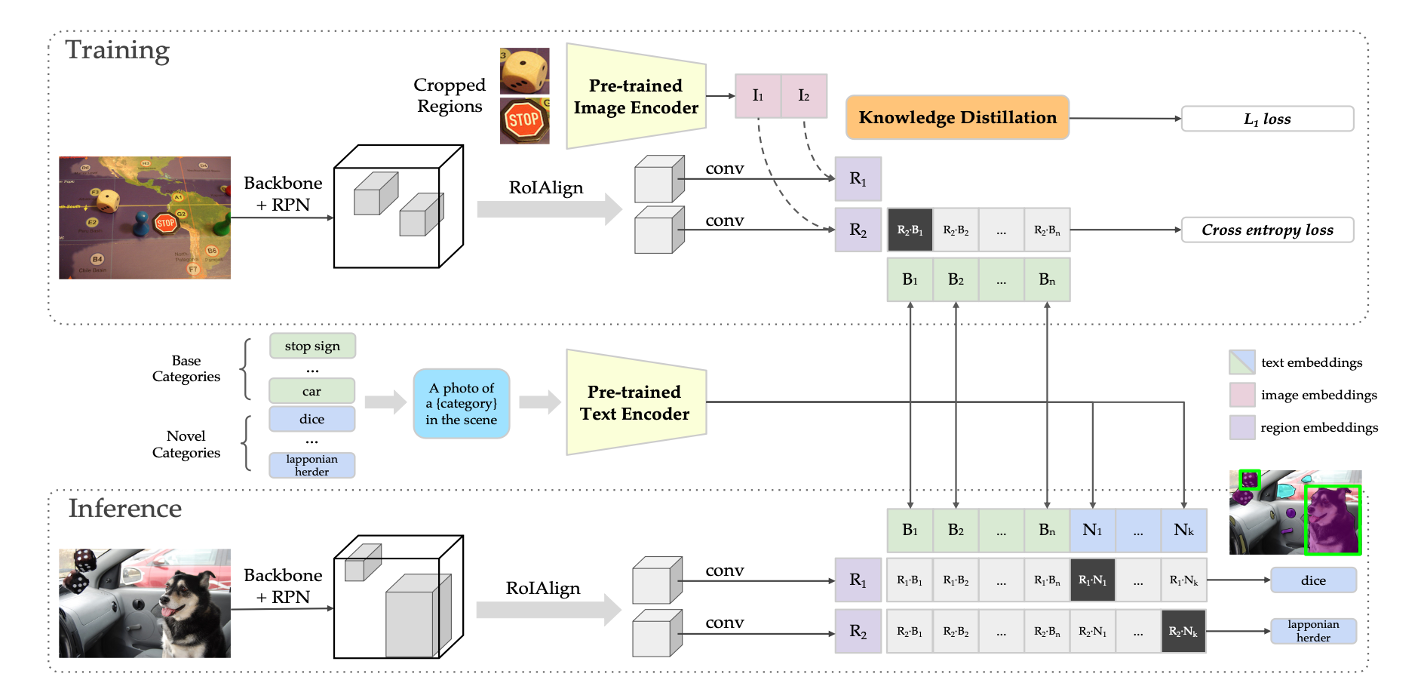
ViLD 的研究重点 在目标检测方法的第二个阶段,也就是得到候选检测框,proposal,之后。文章的使用CLIP思想,还是最简单的 分别抽取文本和图片特征,然后通过点积计算相似度。
这里的Pre-trained ImageEncoder和Pre-trained TextEncoder是CLIP预训练得到的。权重一直是冻住的。
先来看训练部分。先将 图片标注区域 的图像裁剪出来,通过预训练Image Encoder 得到标注区域的image embeddings,也就是红色部分。与此同时,通过Mask R-CNN,产生了一系列的region embeddings。也就是紫色部分。image embeddings和region embeddings需要进行知识蒸馏,这是第一个Loss函数。
文本这边,我们将 基本类别,使用prompt转化成文本后,送到预训练的Text Encoder,得到text embeddings。也就是绿色部分。将紫色部分的region embeddings和绿色部分的text embeddings进行点积,这是第二个loss函数。
再来看推理部分,将基本的类别和新增的类别,使用prompt转化成文本,分别输入Text Encoder产生text embeddings。这里基础类别表示为绿色,新增的类别表现为蓝色。与此同时通过Mask R-CNN,产生了一系列的region embeddings,然后将region embeddings和text embeddings进行点积,然后使用softmax归一化。取最大值的类别作为该区域的预测结果。
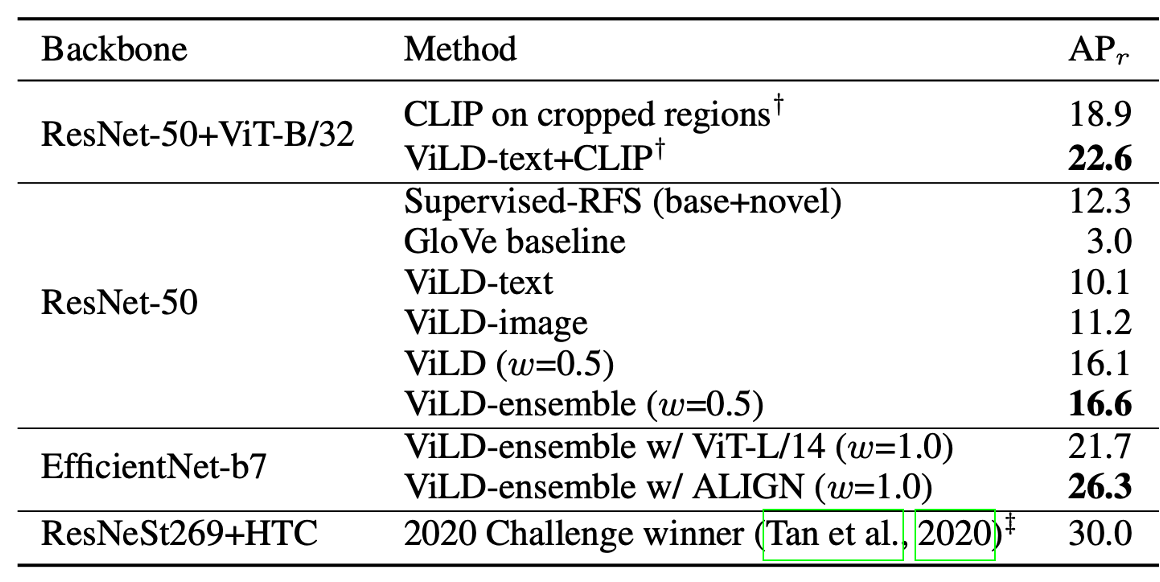
这里的评价指标APr是新的类别,模型没有见过,所以可以做zero-shot检测。可以看到ViLD在新增类别上的精度大幅度超过了之前的有监督的方法。
Conclusion
可以看出,对CLIP的使用,大致可以分为三类
第一个是最简单的情形。
就是把图像或者文本,通过CLIP的预训练encoder,得到一个非常好的特征。于是将这个特征和原有的特征进行融合,或者是直接使用这个特征。CILP4clip,就是用的这个方法。
第二个方法。是利用CLIP生成的特征,来作知识蒸馏,能够帮助现有模型学得更好,收敛更快。比如CLIPasso就使用到了image encoder来作知识蒸馏。
第三个方法。是在第二个方式的基础上,借助对比学习的思想,设计更复杂的多模态学习方式,比如说ViLD。
References
Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International conference on machine learning. PMLR, 2021.
•Zhou, Ce, et al. “A comprehensive survey on pretrained foundation models: A history from bert to chatgpt.” arXiv preprint arXiv:2302.09419 (2023).
•Gu, Xiuye, et al. “Open-vocabulary object detection via vision and language knowledge distillation.” arXiv preprint arXiv:2104.13921 (2021).
•Li, Boyi, et al. “Language-driven semantic segmentation.” arXiv preprint arXiv:2201.03546 (2022).
•Vinker, Yael, et al. “Clipasso: Semantically-aware object sketching.” ACM Transactions on Graphics (TOG) 41.4 (2022): 1-11.
•Han, Xu, et al. “Pre-trained models: Past, present and future.” AI Open 2 (2021): 225-250.
•Luo, Huaishao, et al. “CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval.” arXiv: Computer Vision and Pattern Recognition, Apr. 2021.
•Luo, Huaishao, et al. “CLIP4Clip: An empirical study of CLIP for end to end video clip retrieval and captioning.” Neurocomputing 508 (2022): 293-304.
https://zhuanlan.zhihu.com/p/607106157







