
万字解读~~~扩散模型和跨模态生成(内含数学推导)
Diffusion model and cross-modal generation

最近在 AI 作画这个领域,基于Diffusion的各种模型 发展十分迅猛,比如DALLE2、Stable Diffusion、midjourney等等。可以通过一段prompt生成精美的图片,效果非常惊人,有很广阔的商业前景。
除了图像,Diffusion也有用在音频生成领域,可以通过文本来生成对应的音频
还有现在比较热门的视频生成,这是来自meta的make a video。这里输入的是机器人在时代广场跳舞,它就会生成一个几秒钟的视频,同样也使用到了Diffusion model
本文中,我会先详细介绍Diffusion model的原理,并进行数学推导,包括扩散模型的整体概念、前向扩散、逆向扩散和损失函数。
然后再选取两个代表性的跨模态生成模型,文本生成图像的DALLE2,和文本生成视频的Make-A-Video,做进一步的介绍。最后是对Diffusion model的总结和评价
Diffusion model
Concept
先讲讲生成式模型的概率。
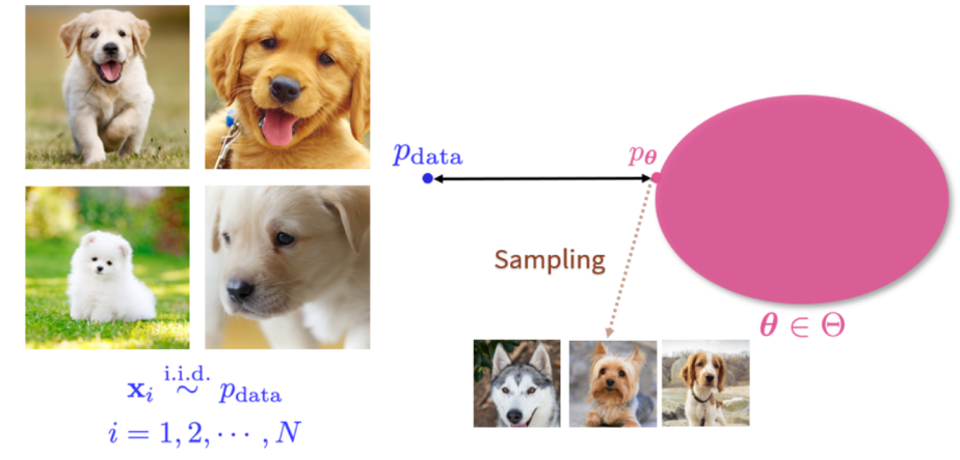
所谓生成式模型,就是给定训练数据,我们要生成与该数据分布相同的新样本。
这张图的左边是一个训练集,里面所有的图片 都是从某个数据P_data中 独立同分布 抽取出的随机样本。
右边就是生成式模型,他目标是找出一个分布P_theta使得它离P_data的距离最近,这样就能从P_theta中,源源不断的抽样得到新的图片。
这并不是一件简单的事情。因为图像的维度很高,我们很难遍历整个空间。此外,我们能观测到的数据样本也有限。

Diffusion model的灵感来自于非平衡热力学。它定义了一个马尔可夫链,一步步的 将随机噪声 加入到样本,然后通过学习逆向扩散过程,从噪声中构建所需的数据样本。引入的噪声会导致信息的衰减,再通过“去噪”尝试还原 原始数据,通过这样多次迭代,能够使模型 在给定噪声输入 的情况下,学习生成新图像。
它分为两个过程,一个是前向过程,一个是逆向过程。
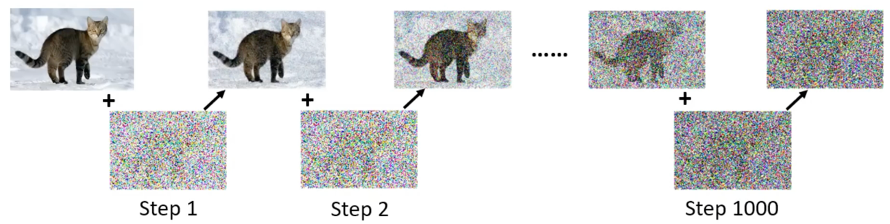
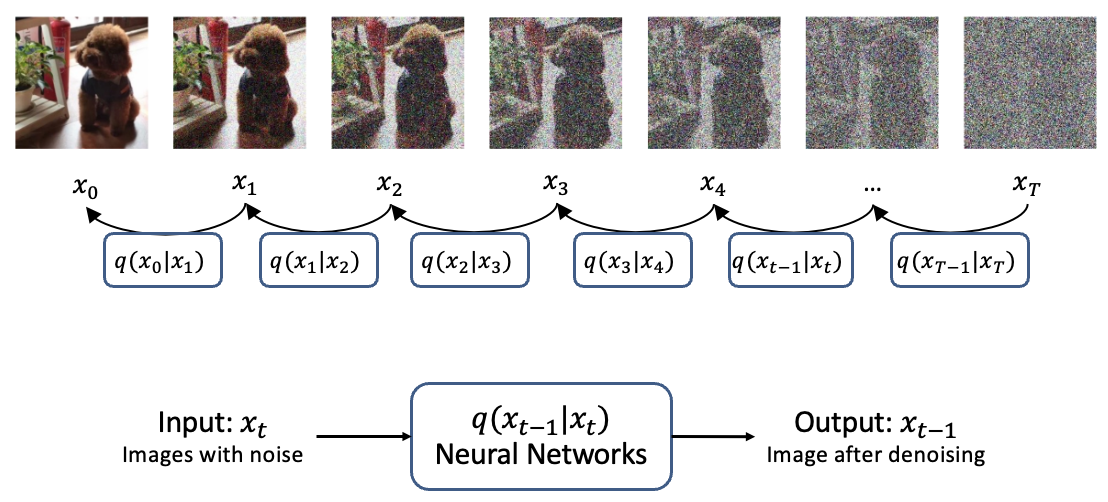
前向过程是这样的。一开始的图片,比如这里的小猫图片,它是有明确的分布规律的,然后在前向的过程中一点点的添加噪声,比如在添加1000次之后,我们就得到了右边的这个近乎于纯噪声的图片。

逆向过程是从一个纯噪声的图片,一步步进行去噪,以得到我们想要的高质量的图片。之所以要有一个前向过程,是因为我们需要 用加噪声之前的图片作为标签,让模型学习噪声是如何产生的,这样才可以反过来去噪。
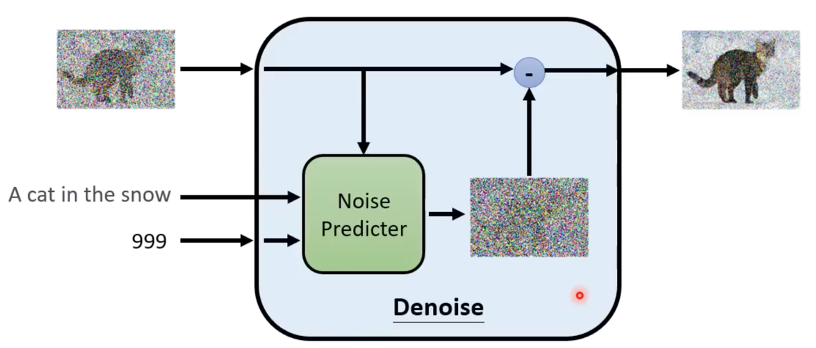
这是在实际应用中,进行一次去噪的示意图,我们将含有噪声的图片、文本表述和当前的步数 输入进神经网络,预测得到这一步对应的噪声,再将含有噪声的图像减去预测出的噪声,就得到了去噪之后的图像。这里的Noise Predicter在每一次去噪中都是同一个模型,共享参数的。因此,为了对不同的step做区分,它需要输入步数t,比如这里的999,相当于一个位置编码。
Forward diffusion process
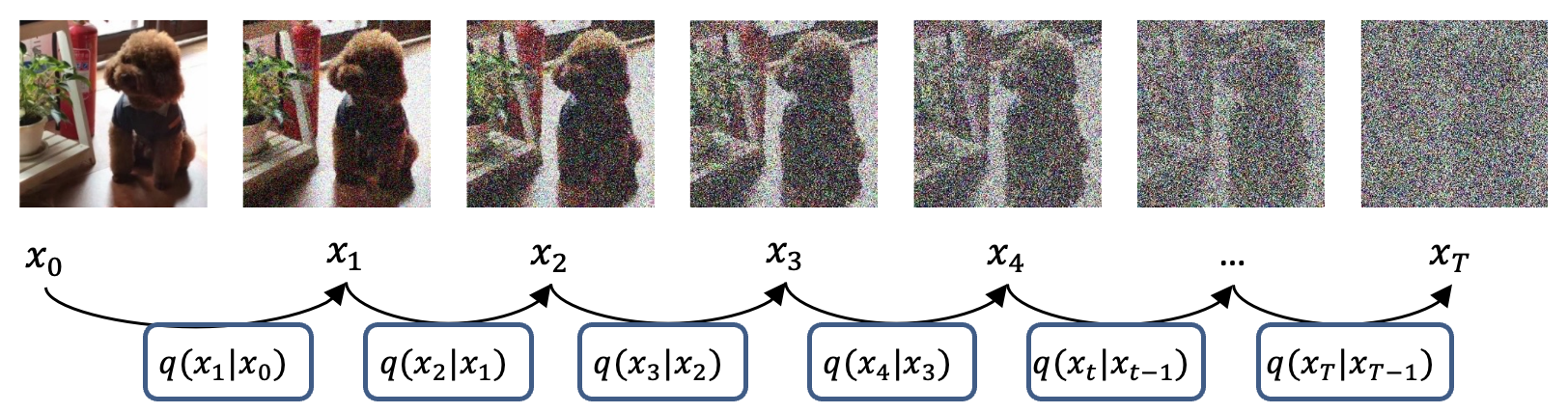
这是前向过程的示意图
现在用X来表示我们的样本,它的下角标t就是当前的时间步。
原始的,没有添加过任何噪声的图片,就是X0,第一次添加噪声后的图像就是X1,给X1添加噪声后的图像是X2,以此类推。
X的下标越大,对应的图像噪声也越大。最后的图像,X大T,经过T次迭代,等价于一个各项同性的高斯分布。
这里我们需要记住的一点是,Xt-1添加噪声后会得到Xt,Xt去除噪声后会得到Xt-1,后面的数学推导中会大量涉及这一点。
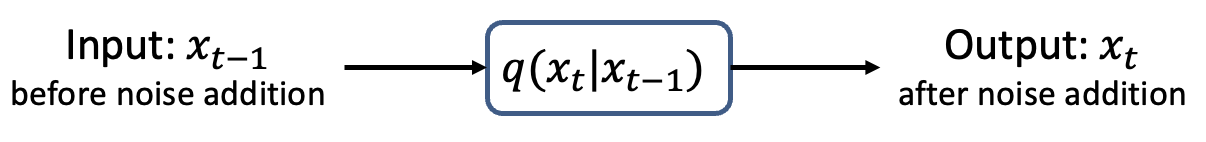
现在定义一个函数q,它的作用,就是给输入的图像 添加噪声,输入X_t-1它就会返回一个添加了一些噪声的图像,X_t。
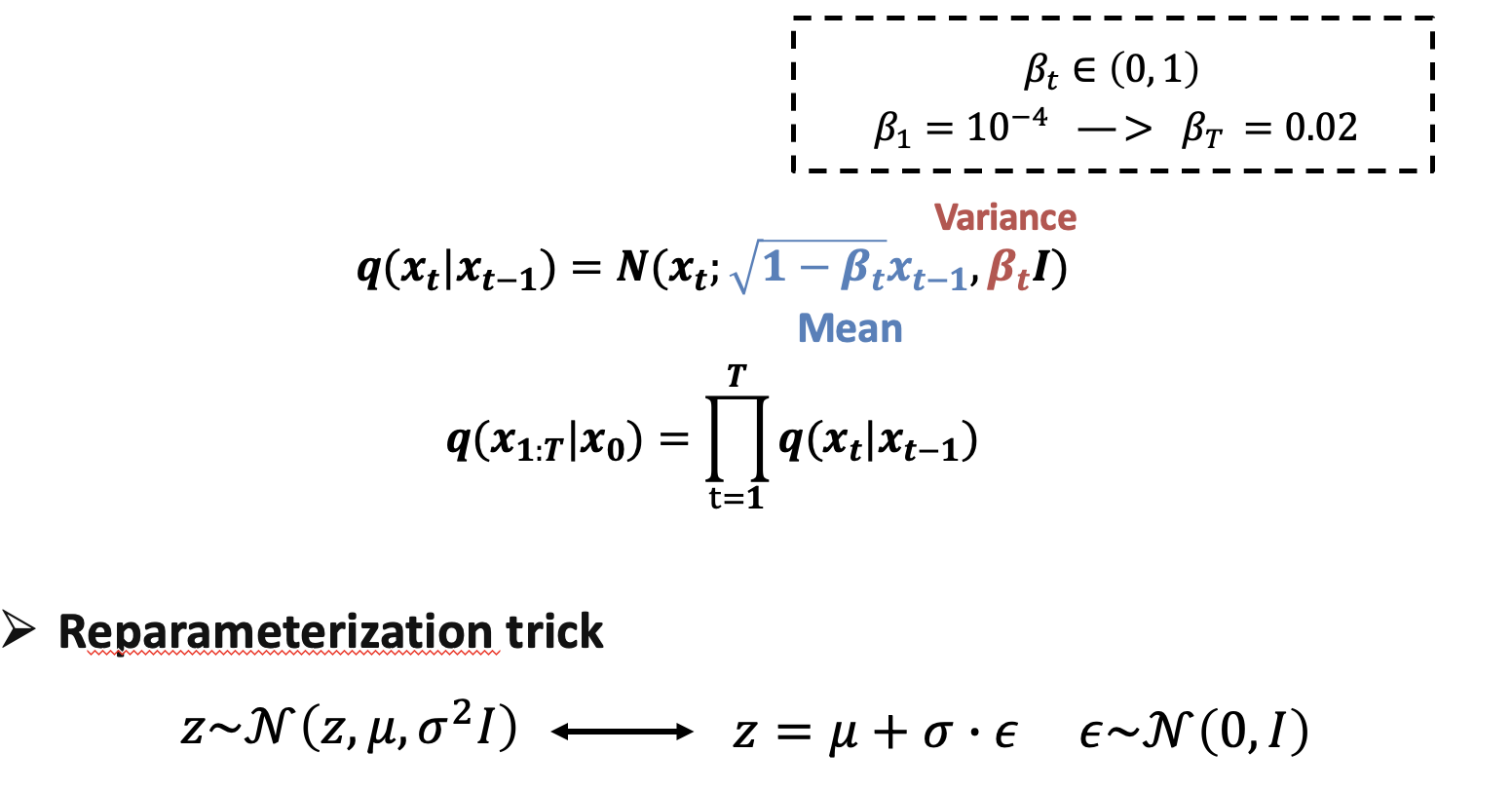
我们来看q的定义,它是从X_t-1得到X_t的过程,服从均值为根号下1-β_t乘以x_(t-1),方差为β_t 的高斯分布
也就是让图像X_t-1 的每一个像素点 都乘以根号下1-β_t,再加上方差为β_t的噪声
这个β_t是我们自己预先设定的 超参数序列。因为刚开始的时候,在图片中加入一点噪声就会有很明显的效果,但后面需要的噪声 会越来越多。所以一般的β_t,是随着时间步的增加而变大的。在论文DDPM中,𝛽_1取值为10的负4次方,β_t的取值为0.02。
可以发现,加入的噪声只由β_t和X_t-1决定,这个过程是固定的,并不需要学习。而且也不难发现,X_t的生成,只依赖于上一步的X_t-1,也就是说加噪的过程是一个马尔可夫链过程。
既然每一步都是固定的,那么并不需要一步一步的从X_0算到X_t。只要有了X_0和β_t的序列,就可以直接计算出来X_t。
加噪过程 需要从高斯分布中 随机采样一个样本,随机变量不可导,因此是无法计算梯度的。因此我们需要通过重参数化技巧来使得他可微。
假如 有一个Z,它是从一个均值为μ方差为σ^2(sigma)的分布中采样得到的。那么我们可以 引入一个 服从标准高斯分布的 随机变量 ϵ (epsilon)。
我们可以把Z重写为 μ+σ∙ϵ。
于是,我们就把随机性引到了ϵ上,这样不仅能方便计算,也能使采样的过程可导,这个技巧叫做重参数化,在后面的推导中会使用到这一技巧。

现在我们先定义α_t,它等于1-β_(t ),β_(t ) 是刚才讲过的超参数序列。然后〖定义α〗_t拔等于α从1到小t的累乘。我们会在后面用到这两个东西。
我们先用刚才的重参数化技巧,用X_t-1表示出X_t
然后我们用上面定义的α_t 来代替式子里的β_(t )
既然能用X_t-1来表示X_t,那么我们也可以用X_t-2把X_t-1表示出来。
我们把X_t-2带入X_t,就可以用X_t-2表示出X_t。
然后把框住的这两项,改写为高斯分布的形式。
于是就能通过独立高斯分布可加性,把他们合并起来,形成一个新的高斯分布
再使用重参数化技巧,就能得到X_t关于X_t-2的简洁的表达式。
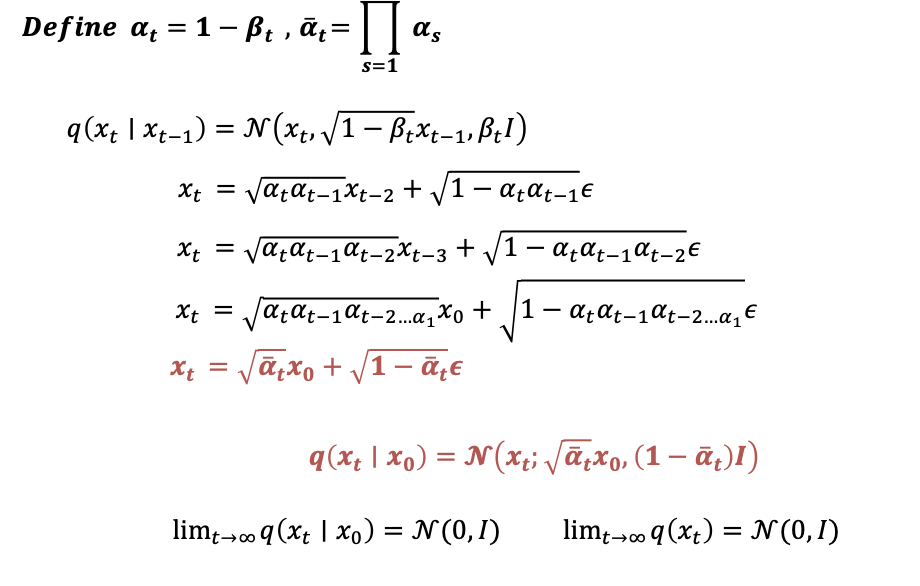
我们现在已经能用X_t-2来表示X_t了。以此类推,最终能用X0来表示Xt
我们之前〖定义α〗_t拔等于α从1到小t的累乘,因此进行替换
将这个式子表示为重参数化之前的形式。
由此我们发现,在给定起始状态X0 和噪声强度系数α 的情况下,任意时刻的状态转移分布,也就是q of Xt given X0,是可以直接算出来的。这个两个标红的式子非常重要的,后面的推导中会经常用到。
α_t拔是关于t递减的,不难看出,这个条件分布最终均值会收敛于 一个均值为0 方差为1 的高斯分布。它的边缘分布最终也会收敛于高斯分布。
以上就是前向扩散的运算过程。
Reverse diffusion process
逆向扩散是将前向扩散反过来,一步步地从高斯噪声Xt推回到原来的图像X_0。但是我们显然是没办法 直接推出来 从X_t到X_t-1的分布的。
所以这就需要用到 深度学习模型,去学习一个参数化的高斯分布P。

这是我们想要预测的高斯分布的表达形式,P of X_t-1 given Xt。
它的均值μ_θ(mu_theta)是一个可以通过神经网络预测的值,主流方法使用的是Unet,方差Σ_θ(sigma_theta)在DDPM这篇论文中是固定值,但是在其他模型,比如说DALLE2里面,这个方差是可训练得到的。
到这里可以看出,正向扩散和逆向扩散的唯一区别是,正向扩散里每一个条件概率的 均值和方差都 是已经确定的,依赖于alpha_t和X0,而逆扩散过程里面的均值是我们网络要学出来。
虽然我们无法得到逆向过程的概率分布Q of X_t-1 given X_t, 但是如果知道X_0,事情就不一样了。
这里需要注意的一点是,X0虽然是未知的,但我们现在先假设他是已知的,进行计算,在后面的计算中会把X0化简掉。

论文这里非常巧妙的使用贝叶斯公式,把未知的逆向公式,用已知的前向公式来表示出来。
可以看到等号右边涉及到了三个前向的公式。
我们之前已经推导过前向过程的公式,前向的加噪过程是服从高斯分布的。
因此,我们可以用右上角的高斯分布的概率密度函数公式,得到这三个式子对应的概率密度函数。代入上面的式子。
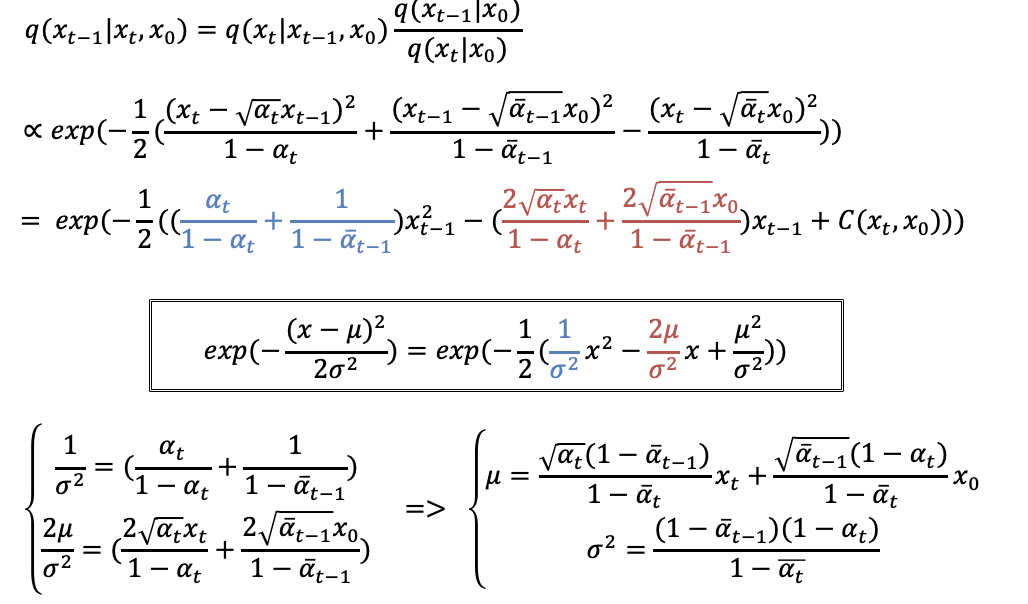
把刚才那三个式子带入后,我们仅仅观察exp的部分,也就是e的指数部分,按照相乘就是指数相加,相除就是指数相减的规则,进行计算。
将平方展开,因为X_t是已知的,X_0我们之前假设它是已知的,这样只有X_t-1是未知的。所以按照X_t-1的指数,合并同类项,得到这个式子,目的是为了凑成高斯分布的形式
方框中的式子是 高斯分布概率密度函数 的指数部分 。可以发现,蓝色的部分对应着X_t-1的二次项,红色的部分对应的是一次项。
那么我们就可以联立这两个等式,也就能解出均值μ 和方差σ^2 。

我们仔细观察一下求解到的均值和方差。
首先看方差,可以看到只和alpha有关,alpha是我们自己定义的,所以方差也是完全已知的一个数。
我们重点看均值这个式子,均值是和X_t和X_0有关。因为在最开始的时候我们假设X_0是已知的,这里就要进行处理了。
之前在前向扩散的推导过程中,我们知道,任意的Xt都能用X0来表示出来
这里我们做一下变换,得到X0关于Xt的表示,再带入计算均值的式子里面。
最终就得到均值的表达式,这里的 ϵ 我们是不知道的,也是唯一需要学的东西,这里我们就要使用神经网络,作者们用的是unet,来预测这个ϵ。由此得到均值。
至此啊,我们就得到了扩散过程的后验分布,q of X_t-1 given X_t X_0,的解析形式。它呢首先还是一个高斯分布,其中均值是关于Xt和 ϵ 的表达式,而方差完全是个常数,和x没有关系。
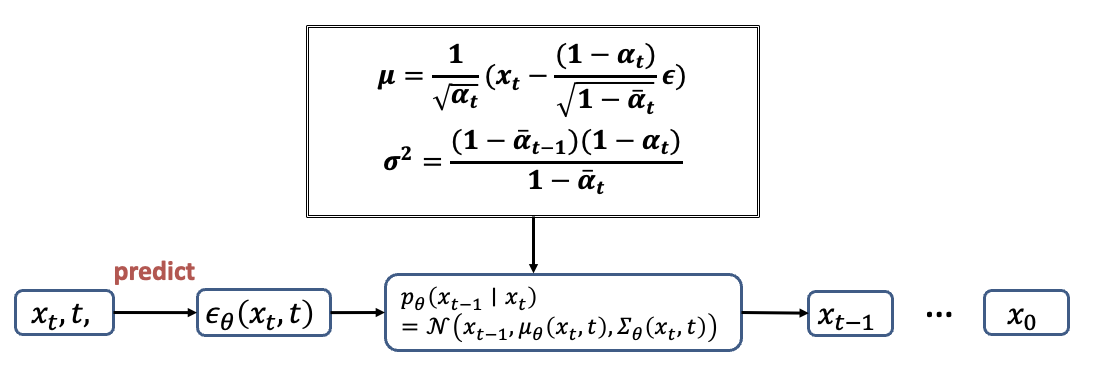
这里用一个流程图来总结一下逆向扩散的过程。我们先将Xt和t输入神经网络,来预测ϵ
然后就能将 ϵ 带入上面的公式,计算得到高斯分布的均值和方差,这样我们就能从这个分布里面采样得到Xt-1。接着又可以通过X_t-1和t-1来预测下一个高斯噪声,以此类推下去就能得到X0。
Loss function
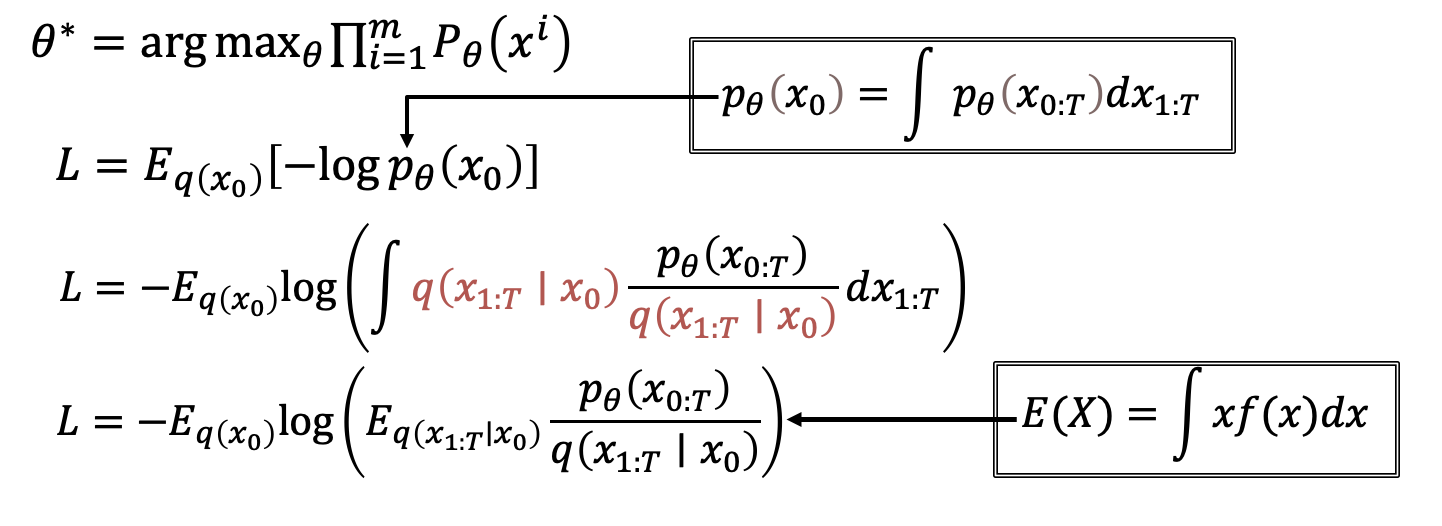
现在我们明白了前向和逆向扩散的过程,但是Diffusion模型是怎样训练起来的呢。换句话说,我们应该怎样学习,去得到一个合理的均值和方差呢。
根据前面的介绍,生成式模型的任务,是找出一个分布P_theta使得它离分布P_data的距离最近。
我们要找的模型theta,就是可以让生成出来的这些图片,产生出来的几率最高的那个theta。所以可以极大似然估计,来表示想要学习出来的结果。
于是Loss函数就可以写成负对数似然的形式,也就是交叉熵。但是计算出这个交叉熵是很困难的,因为P_theta X0没法直接表示出来,这是个隐变量模型,X0是依赖于X1到Xt这些隐变量的。所以接下来要对这个式子进行推导。
第一步是把P_theta X0带入
然后在分子和分母上同时乘以q
这样就能通过期望的定义,转换为最后这个式子。
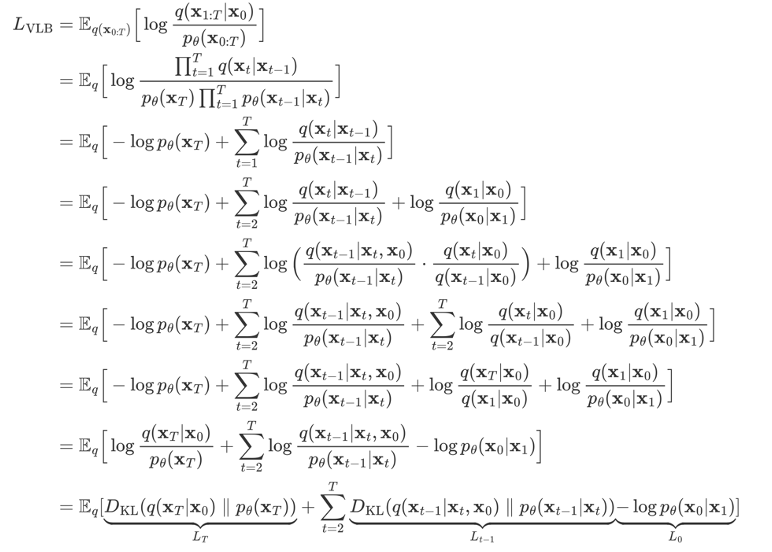
最小化交叉熵就是要找到它的上界,之后就要使用变分推断的方法,来优化这个式子。
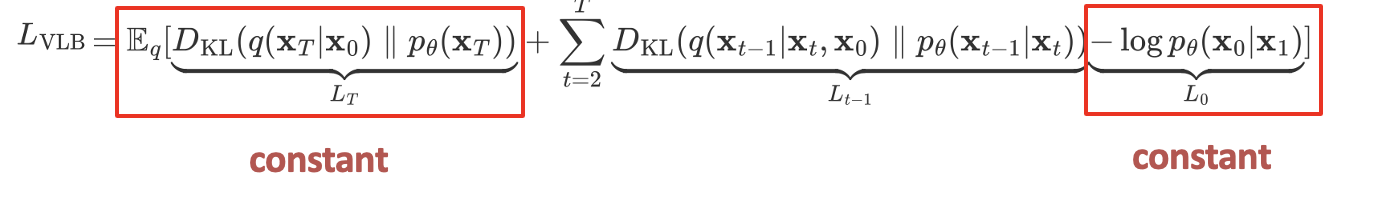
这里对上界L_VLB做进一步的简化,最终将交叉熵的上界用这三个部分来表示,这就是我们要最小化的东西。
第一部分L大T,由于前向过程q没有可学习参数,并且X大T是纯的高斯噪声,所以LT是可以忽略的常量。
最后面的L0其实是一个高斯分布的熵,高斯分布的熵只和它的方差有关,所以L0是一个和theta无关的常数,可以忽略的。所以我们只需要注意中间的这个式子。

中间这部分是用KL散度来表示的,KL散度就是两个分布比值 求log过后的期望,它衡量的是两个概率分布之间的差异,这个式子的含义是,我们希望我们预测的分布p 和正式分布q 尽可能的相似。
把这个式子单独拿出来看,最终化简得到L_simple的形式。
这里的〖 ϵ**〗_**θ 就是我们定义的神经网络,它的输入是第t步的图像,和当前步数t;会预测出一个噪声。将这个预测出的噪声和我们前向过程中记录下来的噪声,也就是ground truth,做一个L_two loss。
所以可以看到,虽然推导过程非常复杂,但最终loss的计算是比较简单直观的。
以上就是diffusion模型的推导过程。
在此,用一句话总结扩散模型,扩散模型本质上是一种参数化的马尔可夫链,使用变分推断进行训练,以便在有限的时间内生成与原始数据分布一致的样本。
DALL-E2


DALL-E2是openai在2022年4月发布的,这个模型在当时的效果是非常惊艳的
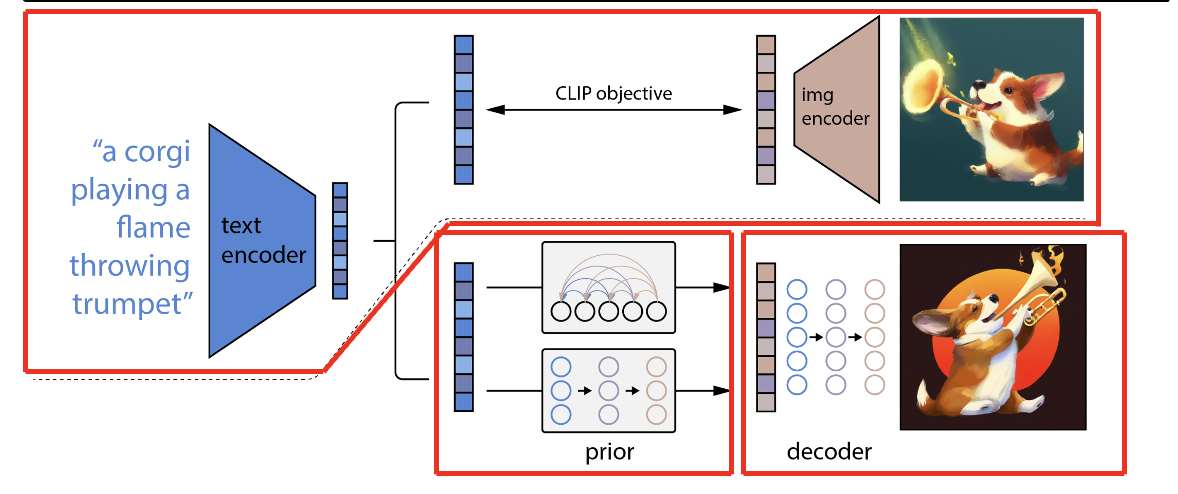
它的任务是给定一段文本描述text,生成与这个文本高度对应的图片。
模型的组成一共有三个部分
一个是虚线上面的CLIP模型,他是用来提取图像和文本的多模态特征,在DAlLLE2这里,这两个CLIP的encoder一直都是锁住的,不会进行任何的训练。
虚线下面的前半部分是,Prior模型,它的作用 是将提取到的文本特征,映射到图像特征的空间
最后是一个decoder,将映射得到的图像特征,生成得到高质量的目标图片,这里采用的就是diffusion modle
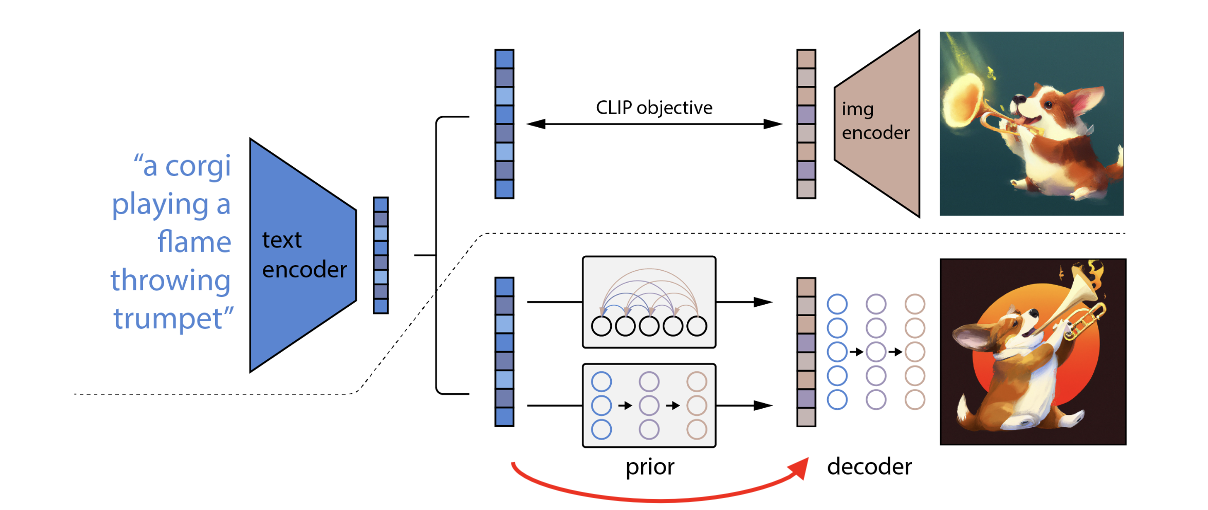
具体是这样做,在训练之前就已经有CLIP模型了,在训练的时候是有图像文本对的。给定一个文本,通过已有的text encoder 得到了文本特征,也就是图中蓝色的部分,因为text encoder是锁住的,所以文本和文本特征是一一对应的关系。
现在希望用这个文本特征,得到对应的图像特征。因为在训练的时候有图像文本对,那就可以将图像通过image encoder得到图像特征,作为ground truth,这样就能把prior模型给训练出来了。
在推理的时候,我们将文本输入得到文本特征,再用prior模型预测,就能得到一个类似CLIP生成的图像特征。
最后一步的decoder就很简单了,直接使用diffusion modle来生成想要的图片
这里的prior模型作者尝试过自回归模型和扩散模型,最终选择的是扩散模型。
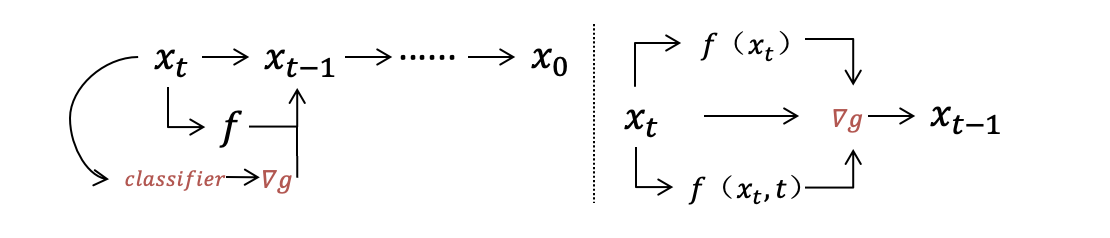
在训练diffusion模型的时候同时用了classifier-free guidance和classifier guidance等信息引导方法,目的是提升图像的真实性,以及训练的效率。
classifier guidanc的做法,是在逆向扩散的过程中,使用一个已有的分类器,对逆向扩散过程中 生成的那些 含有噪声的图片 进行分类,来指导扩散模型的采样和生成。
classifier-free guidance,是不使用任何分类器,而是将条件扩散模型和 联合训练的 无条件扩散模型的分数估计 混合在一起,以引导采样
Make-A-Video

Make-A-Video是mata在去年9月推出的模型,不需要成对的文本视频数据就能进行训练。
它能通过文本描述,生成相对应的视频。
此外它还能两张图片之间,进行平滑的插值,生成视频。
视频的分辨率为768*768
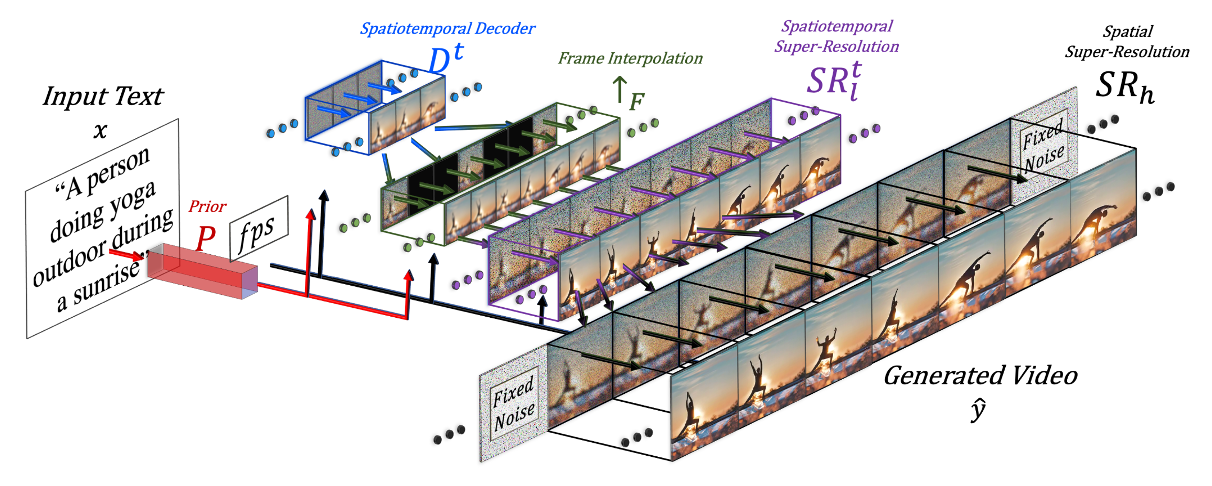
与图像生成领域的繁荣发展不同,视频生成相对要困难很多。主要是因为两个挑战。
第一个原因,是缺乏 具有高质量文本视频对 的大规模 数据集。
第二个原因,是因为文本和图像都是静态的,但视频是动态的,文本很难展现出 视频中事件 的细节
为解决这两个问题,Make-A-Video的作者团队,利用现成的,基于Diffusion的,图片生成模型,学习 文本和视觉世界 之间的对应关系,并使用未标记视频数据,无监督地学习真实运动。
Make-A-Video模型分为三个独立的部分。
第一个是已有的,基于Diffusion的图片生成模型
第二个是时空模块,用于将网络的building blocks扩展到时间维度
第三个是一个插值网络,能够通过 帧插值 来增加 生成视频的帧数,或者通过 帧外推 来延长视频长度。
这三个部分都是独立训练的,第一个图片生成模块是已有的。第二个和第三个模块要解决的问题,是生成视频的连贯性。这里是新增加了一个时空维度,所以只使用视频就可以单独进行无监督训练了。
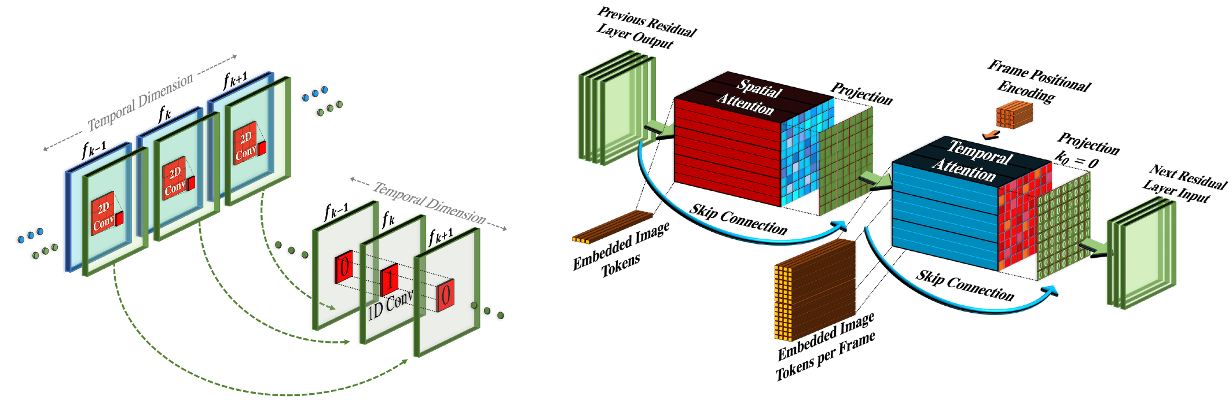
这里简单看一下第二个模块,时空模块,分为两个部分。
左边是伪3D卷积层,它在每个2D卷积层之后叠加一个1D卷积,有助于空间轴和时间轴 之间的信息共享。
右边是伪3D注意力层。作者将 维度分解策略 扩展到了注意力层,在每个空间注意层之后,叠加一个时间注意层。
值得注意的是,时空模块解决的是 多张图片 的连贯性,而不解决文本和视频的相关性,因此可以直接使用未标注的视频,进行无监督的训练
文章最后,作者提到了两个技术限制
第一点是。那些只能在视频中推断出来的关联,模型是无法学习的。比如说,没办法生成一个人从左到右挥手的视频。
第二点是。无法生成包含多个场景和事件的更长的视频
Comments
最后,我想谈谈关于Diffusion model的总结和评价。首先是它的优点
第一个优点是,它是非自回归的。自回归的意思是,在生成很高维的数据的时候,是一个维度一个维度去生成的,比如GPT就是一个典型的自回归语言模型。对于图像来说,这种方法是非常费时的,而Diffusion model没有这个问题。
第二个优点是相比于之前的模型,比如Gan、VAE。Diffusion model只涉及一个神经网络,会更加稳定,网络架构更加灵活。
第三个优点是使用变分推断。因为在模型容量有限,而数据量非常大的时候,变分推断 能更好的捕获 数据主要的分布。Likelihood model希望学习到整个数据集中的每个细节,这个是非常困难的,我们通过变分推断,可以忽略一些特别困难的细节。
最后一点是,它有很高的生成质量,在各个领域都有很大的潜力。
再来谈一下Diffusion model的缺点。
首先,相比来说Diffusion model会使用更多的计算资源和时间。
它生成的逆过程是很长的,DDPM中的大T是等于1000的,也就是说要计算Unet 1000步才能生成一个样本。当然现在也有更多的工作,在研究如何减小生成的步数。
最后一点是,它的likelihood是计算不出来的,只能得到它的变分下界。虽然说这一点并不会影响模型的训练。但如果我们能求出likelihood的话,我们可能就能更好的理解Diffusion model,看看这样一类模型 有没有一些潜在的归纳偏置,它的可解释性是什么样子的。因此如果能够拿到它的likelihood,在研究方面还是很有价值的
References
•Ho, Jonathan, Ajay Jain, and Pieter Abbeel. “Denoising diffusion probabilistic models.” Advances in Neural Information Processing Systems 33 (2020): 6840-6851.
•Song, Jiaming, Chenlin Meng, and Stefano Ermon. “Denoising diffusion implicit models.” arXiv preprint arXiv:2010.02502(2020).
•Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
•Cao, Hanqun, et al. “A survey on generative diffusion model.” arXiv preprint arXiv:2209.02646 (2022).
•Ramesh, Aditya, et al. “Zero-shot text-to-image generation.” International Conference on Machine Learning. PMLR, 2021.
•Ramesh, Aditya, et al. “Hierarchical text-conditional image generation with clip latents.” arXiv preprint arXiv:2204.06125(2022).
•Dhariwal, Prafulla, and Alexander Nichol. “Diffusion models beat gans on image synthesis.” Advances in Neural Information Processing Systems 34 (2021): 8780-8794.
•Luo, Calvin. “Understanding diffusion models: A unified perspective.” arXiv preprint arXiv:2208.11970 (2022).
•Bao, Fan, et al. “One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale.” arXiv preprint arXiv:2303.06555 (2023).
•Kong, Zhifeng, et al. “Diffwave: A versatile diffusion model for audio synthesis.” arXiv preprint arXiv:2009.09761 (2020).
•Singer, Uriel, et al. “Make-a-video: Text-to-video generation without text-video data.” arXiv preprint arXiv:2209.14792(2022).
•Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013).
•Nichol, Alex, et al. “Glide: Towards photorealistic image generation and editing with text-guided diffusion models.” arXiv preprint arXiv:2112.10741 (2021).
•刘华峰, 陈静静, 李亮, 鲍秉坤, 李泽超, 刘家瑛, & 聂礼强. 跨模态表征与生成技术. 中国图象图形学报, (6).
•https://lilianweng.github.io/posts/2021-07-11-diffusion-models/#forward-diffusion-process







