
CVPR 2023:Query-Dependent Video Representation for Moment Retrieval and Highlight Detection
Baseline (Moment-DETR)
视频时刻检索(Video Moment Retrieval)任务在形式上是指,给定一个未剪辑的视频和一个自然的句子查询,该任务旨在识别一个特定视频段的开始和结束时间戳,该视频段包含语义上与给定句子查询相对应的感兴趣的活动。Highlight Detection任务是指对每个video clips去判别是否为Highlight。
论文的baseline是Moment-DETR(QVHIGHLIGHTS: Detecting Moments and Highlightsin Videos via Natural Language Queries)。在过去,尽管Moment Retrieval和Highlight Detection这两项任务有许多共同的特征(例如都需要学习用户文本查询和视频片段之间的相似性),但它们通常被单独研究,主要是由于缺乏在单一数据集中支持这两项任务的注释。而这篇论文首次使模型能够同时完成Moment Retrieval(MR) 和Highlight Detection(HD),并提出了QVHighlights 数据集。
作者从用于目标检测的DETR中获得灵感设计了Moment-DETR,这是一个端到端的Transformer Encoder-Decoder架构,将时刻检索视为直接的集合预测问题。通过这种方法,作者有效地消除了在时刻检索方法中常见的任何手动设计的预处理(如提议生成)或后处理(如非最大抑制)步骤的需要。作者进一步在编码器输出上添加了一个显著性排名目标,用于HD。尽管Moment-DETR在其设计中没有编码任何人类的先验知识,但他们的实验表明,与高度工程化的架构相比,它仍然具有竞争力。
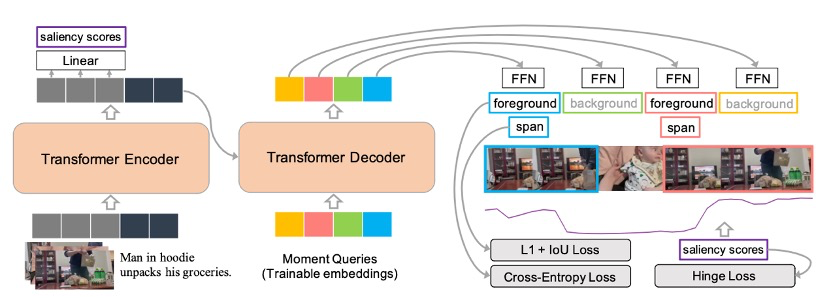
Moment-DET 模型概述。使用Transformer Encoder-Decoder和三个预测头来预测saliency score,前景/背景分数和矩坐标。该图中没有显示视频和文本特征提取器。
Motivation
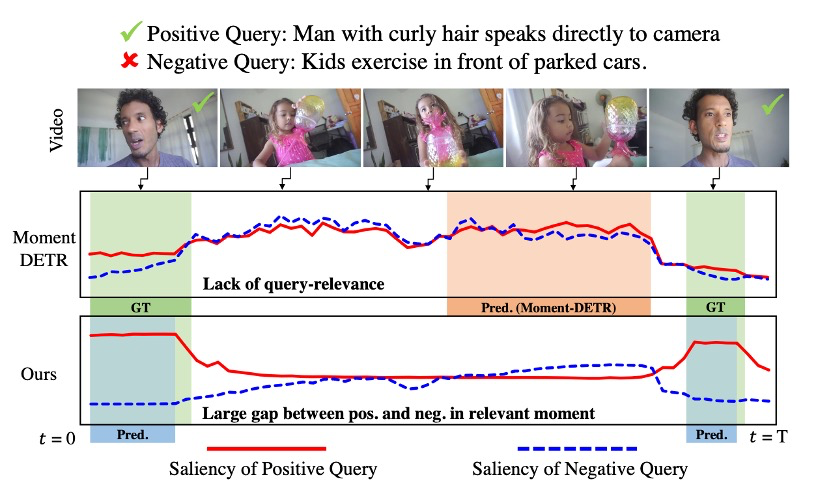
现有的一些研究在处理多模态源(例如视频和音频)时,虽然提出了一些突破性的架构,但是忽视了文本查询的作用。为了验证这个观点,作者对Moment-DETR进行了研究,发现在估计每个视频片段的查询相关性得分时,基线模型经常忽视给定的文本查询。
如图12所示,当给出相关和非相关查询时,高亮度(显著性得分)的比较。作者发现,Moment-DETR的查询基本没有发挥作用,因此可能无法检测到负面查询和视频-查询的相关性;ground-truth(GT)时刻的剪辑中,无论对于正面还是负面查询,显著性得分都较低且相当。另一方面,作者的方法(QD-DETR)的查询依赖表示导致了与视频-查询相关性相对应的显著性得分,并精确地定位了时刻。
为了解决这个问题,他们提出了Query-Dependent DETR (QD-DETR),这是一种能够产生查询依赖的视频表示的模型。主要目标是确保模型对每个片段的预测高度依赖于查询。首先,为了充分利用查询中的上下文信息,作者修改了Transformer Encoder,使其在最初的层中配备了交叉注意力层。通过将视频作为查询,文本作为交叉注意力层的键和值,他们的编码器强制文本查询参与到视频表示的提取中。然后,为了不仅将大量的文本信息注入到视频特征中,而且还能充分利用它,他们还利用了由混合原始对生成的负视频-查询对。具体来说,模型被训练来抑制这种负(无关)对的显著性得分。作者期望的是,文本查询在预测中的贡献度会增加,因为视频有时需要根据文本查询是否相关,产生高的显著性得分,有时则需要产生低的显著性得分。最后,为了应用动态标准来标记每个实例的高亮部分,作者部署了一个显著性token来代表整个视频,并将其作为输入自适应的显著性标准。通过结合所有的组件,他们的QD-DETR通过整合源和查询模态,产生了查询依赖的视频表示。这进一步允许在transformer encoder中使用位置查询。
这篇论文的主要贡献有以下三点
提出了一种新的检测变换器,名为Query-Dependent DETR,用于视频理解中的时刻检索和高亮检测任务。QD-DETR引入了一个交叉注意力层,以利用文本查询中的上下文信息,并将视频-查询对组合起来,生成查询依赖的表示。
为了保持查询依赖的视频表示的多样性,定义了一个输入自适应的显著性预测器。简单来说,显著性标记是一个随机初始化的可学习向量,当它被添加到编码的视频标记的序列中并通过变换器编码器进行投影时,它就变成了一个输入自适应的预测器。
通过交叉注意力编码器确保了查询的贡献,同时通过负对训练强制模型学习查询和视频之间的关系,防止在不考虑查询的情况下解决问题。
Methodology
时刻检索(MR)和高亮检测(HD)都有一个共同的目标,那就是找到与文本查询相匹配的优选时刻。给定一个由L个片段组成的视频和一个由N个词组成的文本查询,我们分别用冻结的视频和文本编码器(如CLIP)提取出他们的表示,记为{v1, v2, …, vL}和{t1, t2, …, tN}。有了这些表示,主要的目标就是在视频中定位中心坐标m_c和宽度m_σ,并为每个片段排名高亮得分(显著性得分){s1, s2, …, sL}。
对于MR,利用Transformer的一个直接的方法是将时刻的预测作为一组片段,或者根据片段的预测生成时刻。为了利用多模态信息,过去的方法要么简单地将各模态的特征连接起来,要么插入文本以形成向transformer decoder的时刻查询。然而作者认为,视频和文本查询之间的关系应该被仔细考虑,而不是简单的连接,因为MR/HD需要每个视频片段都与文本查询有条件地进行评估。
QD-DETR的整体架构图如图13。使用Moment-DETR作为baseline。给定一个视频和文本查询,我们首先从固定的网络中提取视频和文本特征。这些视频和文本特征被传送到交叉注意力变换器(Cross-Attentive Transformer Encoder)。这个过程确保了文本查询对视频标记的一致贡献,并与Learning from Negative Relationship一起,构建了查询依赖的视频表示。然后伴随着saliency token,视频标记被给予transformer encoder。在这个过程中,saliency token记被转化为自适应的显著性预测标准。然后,encoder的输出被处理,以计算HD和MR的损失:具体来说,encoder的输出标记直接投影到saliency score,并优化HD,同时也提供给带有可学习时刻查询的transformer decoder,以估计查询描述的时刻。最后,通过预测的和对应的GT时刻之间的差异,计算MR的损失。
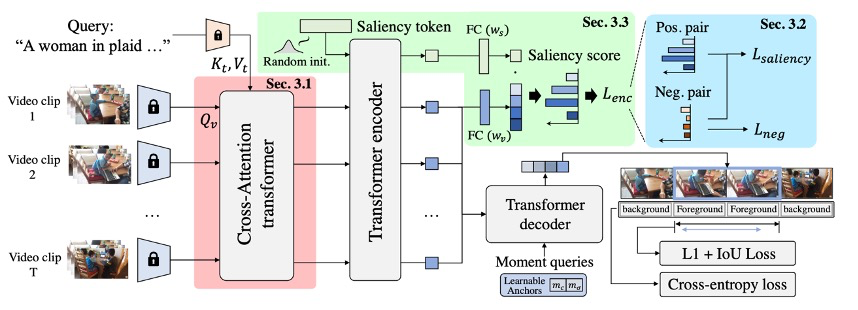
Cross-Attentive Transformer Encoder
这一节的内容,对应的是图左侧的红色部分。
Encoder对于MR/HD的主要目标是产生带有查询相关度信息的片段表示,因为这些特征直接用于检索匹配查询的时刻和预测片段的saliency score。然而,现有工作的编码过程可能不能确保每个片段都有查询条件。例如,Moment-DETR简单地将视频和查询连接起来作为自注意力层的输入,如果视频片段之间的高相似性压倒了文本查询的贡献,那么查询可能就没有太大的作用。
为了将文本上下文引入每个视频片段表示,作者在encoder的最初几层之间都加上了视频源和查询模态之间的交叉注意力层(Cross-Attentive Transformer Encoder)。具体来说,交叉注意力层的查询是通过将视频片段投影为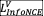 来准备的,而键和值是通过查询文本特征计算得到的,即
来准备的,而键和值是通过查询文本特征计算得到的,即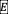 和
和 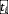 。
。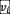 , 和
, 和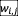 是查询、键和值的投影层。交叉注意力层按照以下方式操作:
是查询、键和值的投影层。交叉注意力层按照以下方式操作:

其中d是投影键、值和查询的维度。由于softmax得分只在查询元素上分布,所以视频片段是以与文本相似度成比例的文本查询的加权和来表示的。注意力得分然后通过MLP投影并集成到原始视频表示中,作为典型的Transformer层。将查询依赖的视频标记,即交叉注意力层的输出。
Learning from Negative Relationship
这一节的内容,对应的是图右上角的蓝色部分。
虽然交叉注意力层明确地融合了视频和查询特征,以便在架构上参与查询信息的中间视频片段表示,但作者认为,给定的视频-文本对缺乏多样性,无法学习一般的关系。例如,单个视频中的许多连续片段通常具有相似的外观,与特定查询的相似性可能是高度可区分的。
因此,模型不仅考虑了与查询相关的视频片段,也考虑了与查询无关的视频片段,这种方法被称为负面配对学习。在负面配对学习中,给定的训练视频-查询对被定义为正面配对,而从不同对中混合视频和查询构造的对被定义为负面配对。如图14所示,在训练过程中,正面配对的视频片段被训练以产生与查询相关性的分段saliency score,而无关的负面视频-查询对被强制具有最低的saliency score。
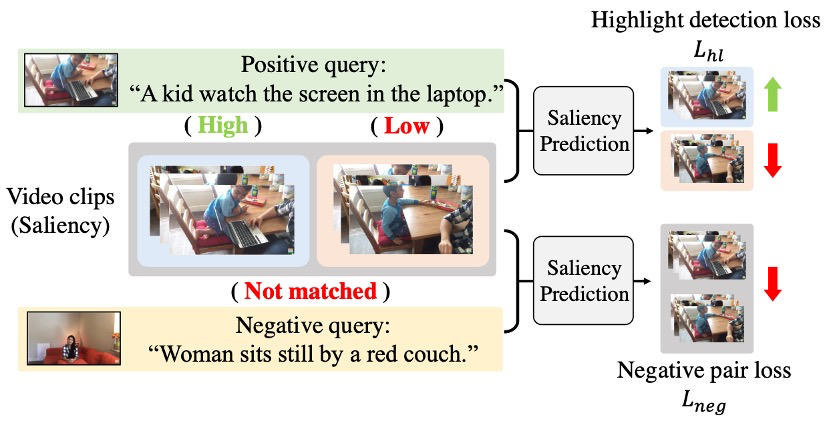
Input-Adaptive Saliency Predictor
这一节的内容,对应的是图上方的绿色部分。
这一节的内容,对应的是图13上方的绿色部分。这个部分提出了一个输入自适应的显著性预测器,这种方法的优点是能够根据输入的视频-查询对的特性,动态地调整显著性预测的标准,从而更好地适应各种不同的视频和查询对,提高了显著性预测的准确性。
对于显著性预测器S(·),一个简单的实现方式是堆叠一个或多个全连接层。然而这样忽视了视频和自然语言查询对的多样性,违背了提取查询依赖视频表示的关键思想。
Input-Adaptive Saliency Predictor的核心思想是使用一个可学习的向量,称为显著性标记,作为预测器。这个显著性标记在被添加到编码的视频标记序列并通过Transformer encoder投影后,能够根据输入的特性进行自我调整,从而成为一个自适应的预测器。
具体来说,首先将显著性标记与查询依赖的视频标记连接起来,然后将这些标记送入变换器编码器进行处理。在这个过程中,显著性标记会根据输入的上下文信息进行重新组织。接下来,显著性和视频标记会被分别通过一个全连接层进行投影,得到的结果就是显著性得分。计算公式如下:
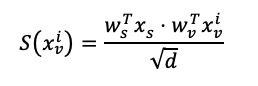
LOSS
这篇文章中,作者使用了几个损失函数来优化他们的模型。下面我将简单解释每个损失函数的意义和计算方法:
Moment Retrieval Loss**:**这个损失函数用于衡量真实时刻和预测时刻之间的差异。它由L1损失、一种改进的IoU损失(LgIoU)以及交叉熵损失组成。L1损失和LgIoU损失用于定位视频中的时刻,而交叉熵损失用于将预测的时刻分类为前景或背景。计算公式如下:
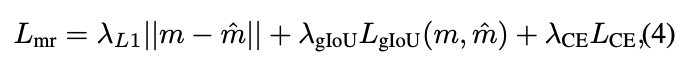
Margin Ranking Loss**:**这个损失函数用于确保高排名的片段的显著性得分高于低排名的片段和负片段。
Rank-Aware Contrastive Loss**:**这个损失函数用于学习精确的显著性等级。它通过对比损失来学习每个片段的显著性得分。
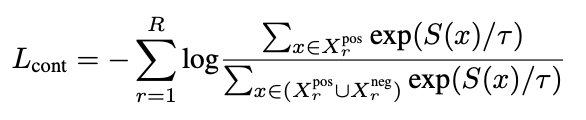
Highlight Detection Loss**:**这个损失函数是Margin Ranking Loss和Rank-Aware Contrastive Loss的组合,用于估计显著性得分。
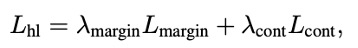
Total Loss**:**
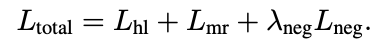
Experiments
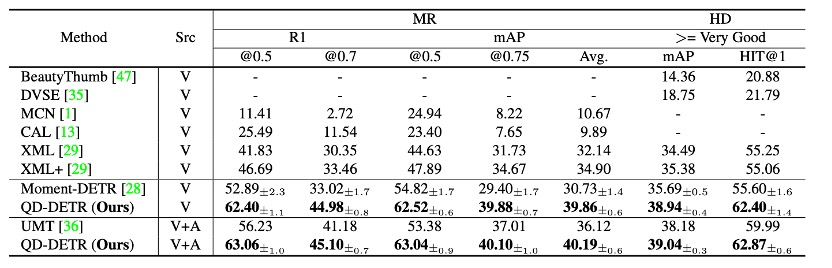
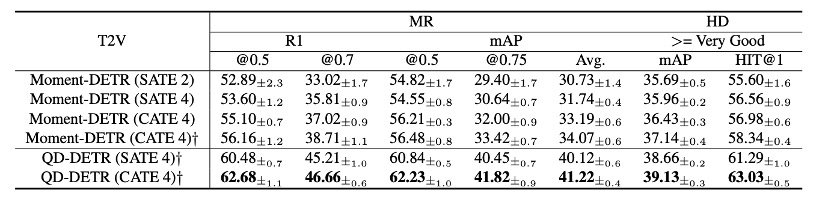
作者使用了四个数据集:QVHighlights、Charades-STA、TVSum和ActivityNet Captions。这些数据集包含了各种类型的视频,如新闻、纪录片、vlog等。作者使用了与基线相同的评估指标。使用了IoU阈值为0.5和0.7的recall@1,以及不同阈值下的mAP。使用了mAP和HIT@1来评估高亮检测。HIT@1是通过最高得分剪辑的命中率来计算的。
在联合学习和预测MR/HD的任务中,QD-DETR在所有评估指标上都超过了最先进的方法。在使用视频源的方法中,QD-DETR在更严格的指标下显示出显著的增长;在高IOU下,它以大幅度的优势超过了之前的最先进的方法。在使用视频和音频源的QD-DETR中,与使用多模态源数据的最先进方法相比,MR的平均指标提高了11.84%。这些结果验证了在文本查询中强调源(仅视频或视频+音频)描述性上下文的重要性。
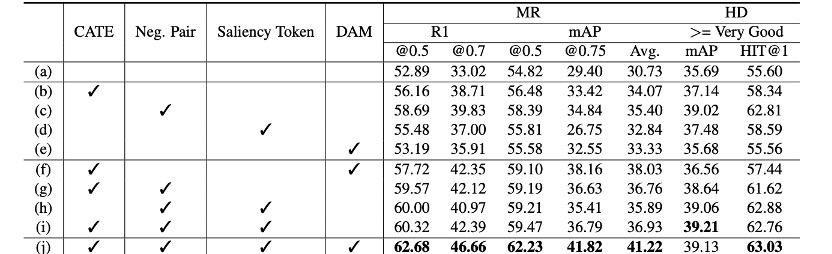
Ablation Study
在消融研究中,作者对每个组件的有效性进行了深入的研究。他们使用了交叉注意力变换器编码器(CATE)和动态锚点时刻(DAM)进行了比较。他们发现,CATE和DAM对于模型的性能提升起到了关键作用。此外,他们还发现,使用更多的自我注意力层并不能带来更好的性能,这证明了CATE的改进主要来自于强调文本查询的作用,而不仅仅是增加了更多的层。
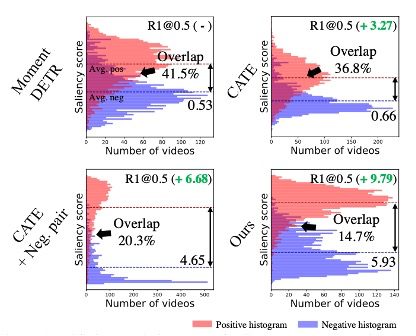
在定性结果部分,作者研究了查询依赖的视频表示如何敏感地反应文本查询上下文的变化。他们发现,查询与视频剪辑的相关性越高,查询的显著性得分就越高。例如,与视频实例完全无关的负面查询具有最低的得分,而半正面查询的得分位于正面和负面之间。此外,他们发现QD-DETR有时会提供比给定的真实时刻更精确的时刻预测。他们认为,对于正面查询,在非相关剪辑中稍微高一些的显著性得分是由于自我注意力层中的信息混合。
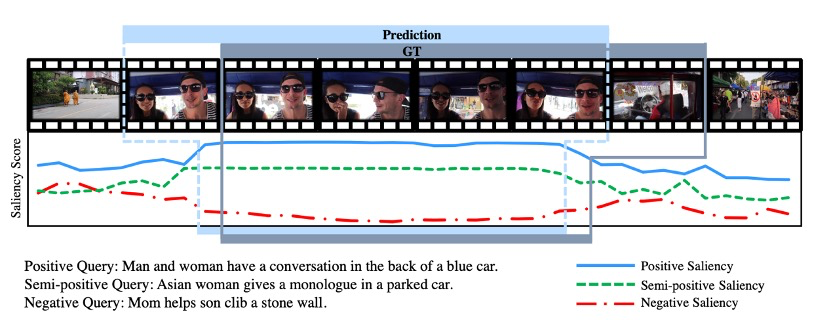
Limitation
尽管文章的目标是强调文本查询在检索相关时刻和估计其与给定文本查询的一致性等级中的作用,但是,如果给定的查询不保持有意义的上下文,例如,提供了噪声文本查询(不匹配或无关的真实文本),那么训练可能不会那样有效。







