CVPR 2023-Towards Generalisable Video Moment Retrieval:Visual-Dynamic Injection to Image-Text Pre-Training
Motivation
视频片段检索(Video Moment Retrieval,VMR)已经在人机交互、智能监控等多种实际应用中进行了广泛研究。但是原始视频通常是没有剧本和结构的,而且不同的人描述同一视频片段时所选择的词汇可能会有所不同。因此,VMR在需要理解视频中任意复杂的视觉和运动模式,以及近乎无限的词汇与它们之间的关系,这是非常困难的。
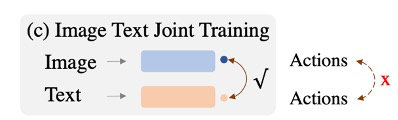
首先,VMR的细粒度检索,相比于传统的图像/视频级别的检索,准确的片段级别的时间标签更难收集。过去(大规模图像-文本预训练模型出现之前),VMR解决方案大量依赖于单模态预训练来理解视觉和文本(如图所示)。然而,如果没有足够的训练数据,从视频和文本中推导出通用的对齐关系以适应新的场景和词汇是非常困难的。

目前的方法主要依赖于大规模的图像-文本预训练模型(如图所示)。然而,这些模型主要关注静态图像和文本之间的关联,而忽视了视频的动态性质。这导致了一个问题:即使在大规模的图像-文本预训练模型的帮助下,VMR模型仍然难以理解和定位视频中的动态变化。

虽然一些方法试图通过在VMR模型中引入额外的序列分析(如LSTM)来捕捉视频变化信息(如图所示),但这些方法往往无法理解描述视频变化的文本短语,因为这些短语在图像文本预训练中被忽视了。因此,这些方法在处理涉及新颖场景和词汇的视频片段检索任务时,往往表现不佳。
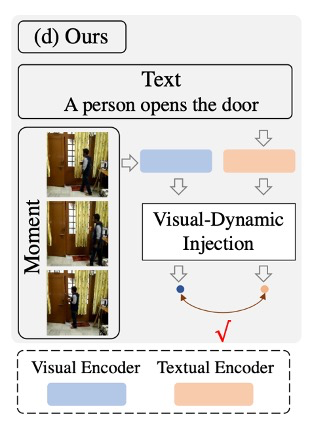
基于以上动机,作者提出了一种名为Visual-Dynamic Injection (VDI)的方法,以增强模型对视频片段的理解(如图所示)。VDI的核心思想是从视频帧中提取视觉上下文和空间动态信息,并明确地强制它们与描述视频变化的短语(例如动词)对齐。通过这种方式,视频中可能相关的视觉和运动模式被编码在相应的text embeddings中,从而实现更准确的视频-文本对齐。
这篇论文的主要贡献有以下三点
首次尝试将视觉和动态信息注入到图像-文本预训练模型中,以实现可泛化的VMR。这种方法弥补了现有图像-文本预训练模型在处理视频变化时的不足。
提出了一种名为视觉-动态注入(VDI)的新方法。VDI是一种通用的形式,可以集成到任何现有的VMR模型中。它通过在训练过程中将视觉-动态信息注入到文本编码器中,使得VMR模型能够从大规模的图像-文本数据中获得的通用视觉-文本对齐中受益。这种方法在推理过程中不会引入额外的计算成本。
实验表明,当在涉及新颖场景和词汇的out-of-distribution splits上进行测试时,VDI方法优势显著。这表明VDI具有优越的泛化能力,能够处理包含新颖场景和词汇的测试样本。
Methodology
论文中提出的视觉动态注入(Visual-Dynamic Injection,VDI)主要包括两个部分:视觉上下文注入(Visual Context Injection)和空间动态注入 (Spatial Dynamic Injection),以在两种模态中都能模拟视觉上下文和空间动态。
首先使用语言解析工具提取查询句子Q中的所有名词块(一个名词及其描述词),这些名词块被认为是目标视频片段中的感兴趣实体,并掩盖Q中的所有其他词语。在这种情况下,将关于视频中静态内容的掩盖句子称为静态查询Qs。相反,作者还构造了另一个动态查询Qd,其中Q中的所有名词块都被掩盖。使用视觉上下文注入和空间动态注入来模拟视频变化,并强制文本编码器将动态查询Qd与它们匹配。通过这种方式,调整后的文本编码器能够为查询句子产生视觉-动态敏感的表示,以确保通过视觉和动态匹配实现更准确的VMR。
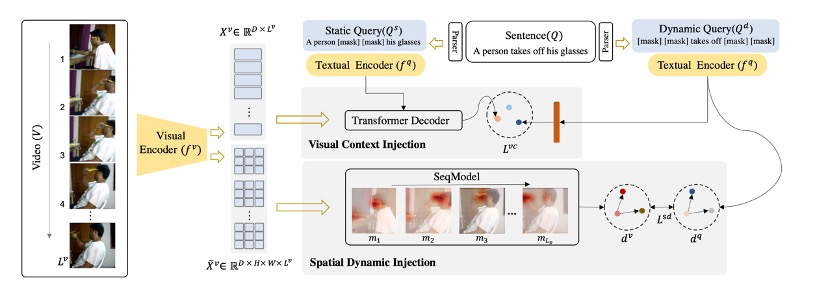
视频V被输入到视觉编码器中,生成图像全局特征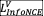 和图像块特征
和图像块特征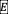 。句子Q被解析成静态查询
。句子Q被解析成静态查询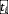 和动态查询
和动态查询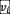 。视觉上下文注入(
。视觉上下文注入(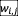 )使
)使 与
与 引导的视觉语境信息保持一致。空间动态注入(
引导的视觉语境信息保持一致。空间动态注入( )使具有空间动态的意识。
)使具有空间动态的意识。
Visual Context Injection
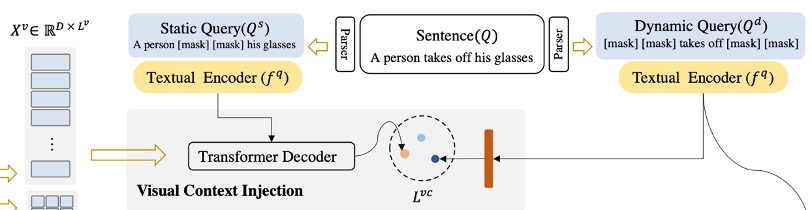
视觉上下文是视频中如何展示与视频变化相关的实体的信息。这种视觉信息可能包括场景的存在(例如,室外或室内)、实体的状态(例如,沸腾或冷水)等。这对于识别和定位涉及特定对象和场景的视频片段非常重要。因此,模型应用了一个 Transformer Decoder,并将视觉上下文信息编码到静态查询 中。具体的做法如下:
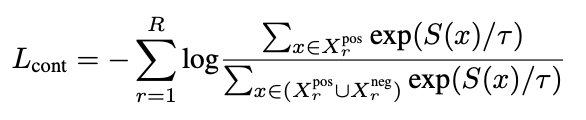
是文本Encoder获得的静态查询q的d维文本特征,为视频帧特征,为Transformer Decoder计算的的视觉上下文感知特征,其三个输入分别对应于查询、键和值。为了将这种视觉上下文信息注入到关注视频中变化描述词的文本编码器中。在计算得到文本Encoder的动态查询特征后,我们当然希望它与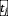 尽可能的接近,于是得到了损失函数:
尽可能的接近,于是得到了损失函数:
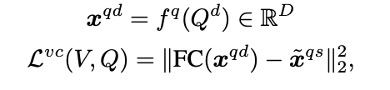
FC(·)是一个线层,通过这种方式,文本Encoder被更新以将动态查询与其视觉上下文对齐,并避免来自无关视频内容的干扰。
Spatial Dynamic Injection
空间动态注入用于捕获视频中不同实体的空间位置随时间变化的信息。这种信息对于理解视频变化至关重要,但是,这种动态信息通常隐藏在视频中复杂的视觉模式中,发现并利用它们来提高文本编码器对相应描述的注意力并非易事。因此,作者们提出空间动态注入,提取视频中显著实体的位置变化,并显式地将这种空间动态性注入到文本Encoder中。
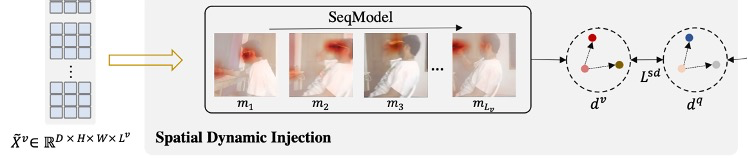
具步骤如下。首先,我们获取每帧的空间特征,这些特征是由卷积神经网络或视觉Transfomer产生的最后特征图。然后采用类似于Transformer的公式为每个视频帧计算一个热图。
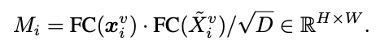
帧级热图是通过每个空间特征和全局图像表示之间的相关性来计算的。因此其视觉信息被编码在图像特征中的显著实体将在热图中产生相应的显著区域。然后将热图展平并将其输入到一个线性投影层中,以计算每帧的空间特征的整体表示。视频中的空间动态性可以用任何序列分析模型给出。

由于在空间特征中降低了视觉信息,不能通过静态查询来探测它们。因此选择一个Transformer Enoder来构建它们的依赖关系,并取平均输出作为视频的空间动态特征。为了将这种动态信息注入到文本编码器中,我们让在不同视频的空间动态特征(V和V’)和相应的文本描述(and ′)之间保持一致的相关性。以此设计得到loss函数。
值得注意的一点:这里使用的空间特征丢失了视频中的所有视觉信息,所以不能直接将它们推向匹配的文本特征,而是通过优化它们与动态查询的相关性一致性。
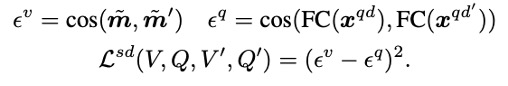
Model Training
在 VMR 中使用 VDI 的一个例子是 Mutual Matching Network (MMN)。在 MMN 中,给定帧级视频特征 和句子特征 ,首先枚举所有的起始-结束帧对,生成= × 个视频片段作为目标片段的候选项。然后通过对所有可能的视频片段应用二维卷积操作得到一个2D 特征图 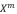 。之后视频片段的特征
。之后视频片段的特征 和查询句子的特征
和查询句子的特征 都会被线性投影到一个公共空间,然后通过余弦相似度 cos(·, ·) 来测量它们的对齐。
都会被线性投影到一个公共空间,然后通过余弦相似度 cos(·, ·) 来测量它们的对齐。
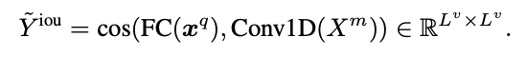
预测的每个片段和查询句子之间的对齐分数 将由目标片段的手动标记的时间边界 (ts, te) 的时间 IoU 监督。除了通过对齐正片,MMN 还会通过对齐负片来进一步优化模型。在这个过程中,VDI 能够通过注入视觉-动态信息来提高文本编码器的性能。这使用了两个Loss,。
将由目标片段的手动标记的时间边界 (ts, te) 的时间 IoU 监督。除了通过对齐正片,MMN 还会通过对齐负片来进一步优化模型。在这个过程中,VDI 能够通过注入视觉-动态信息来提高文本编码器的性能。这使用了两个Loss,。
是基于IoU的损失函数。在视频片段检索任务中,我们的目标是找到与查询句子最匹配的视频片段。这个片段的位置是由一个起始时间点和一个结束时间点确定的。损失函数就是用来衡量模型预测的片段位置(即起始和结束时间点)与真实片段位置的差距的。简单地说,它计算的是模型预测的片段与真实片段在时间上的交集与并集的比值,然后通过最大化这个比值来训练模型。
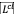 是一种对比损失(Contrastive Loss)。在视频片段检索任务中,除了要找到与查询句子最匹配的正样本片段,还需要确保模型能够区分正样本片段和负样本片段。负样本片段是那些与查询句子不匹配的片段。
是一种对比损失(Contrastive Loss)。在视频片段检索任务中,除了要找到与查询句子最匹配的正样本片段,还需要确保模型能够区分正样本片段和负样本片段。负样本片段是那些与查询句子不匹配的片段。 就是用来衡量模型对正样本片段和负样本片段的区分能力的。它计算的是模型对正样本片段和负样本片段的预测得分的差距,然后通过最大化这个差距来训练模型。
就是用来衡量模型对正样本片段和负样本片段的区分能力的。它计算的是模型对正样本片段和负样本片段的预测得分的差距,然后通过最大化这个差距来训练模型。
以下是本文方法的伪代码
输入:
未修剪的视频 V
查询句子 Q
时间边界标签 (ts, te)
从图像-文本预训练中得到的视觉Encoder 和文本encoder
输出:
更新后的视频片段检索模型
步骤:
生成静态查询句子
和动态查询句子 使用
计算 和 的特征使用
计算视频 V 的特征计算视觉上下文损失
和空间动态损失 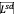
通过最小化
和 来调整文本编码器 使用
计算查询 Q 的特征将视频 V 和查询 Q 的特征输入到
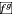
计算损失
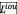 和
和 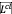
通过最小化
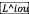 和
和  来优化视频片段检索模型
来优化视频片段检索模型 
Experiments
实验使用了两种评估指标:“R@n, IoU = µ”和“mIoU”。其中,“R@n, IoU = µ”表示在前n个检索到的片段中,至少有一个片段与真实片段的交并比(IoU)大于µ的查询语句的百分比。“mIoU”是所有测试样本的平均IoU。在Charades-STA和ActivityNet-Captions两个数据集上,实验展示了n ∈ {1, 5}且µ ∈ {0.5, 0.7}的结果,以进行公平的identically distributed(IID)切分比较,以及n∈ {1}且µ∈ {0.5, 0.7}以及mIoU的结果,以进行公平的out-of-distribution(OOD)切分比较。
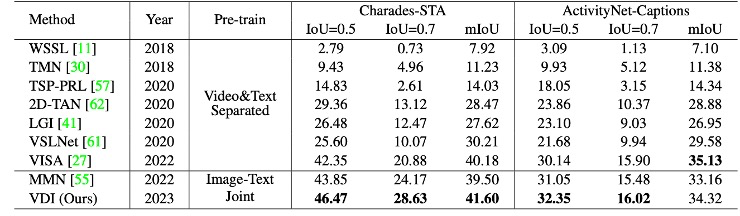
OOD测试
out-of-distribution切分上进行测试时,VDI在两个数据集上都取得了最好的效果。说明在涉及新颖场景和词汇的,VDI表现出显著的优势。
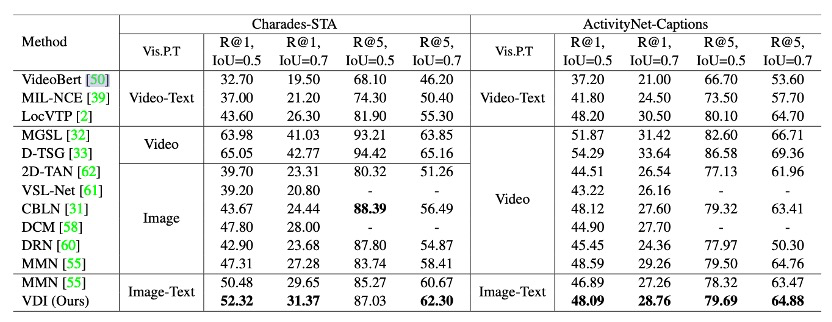
Original Split测试
当将MMN从分离的预训练替换为联合预训练特征时,性能从47.31%增加到50.48%,这表明视觉和文本之间的关联是必要的。通过他们提出的方法(VDI)来增强模型对动作的理解,性能进一步提高到52.32%。从ActivityNet-Captions的结果中,我们可以看到,尽管从基于视频的预训练到基于图像的预训练有一定的性能下降(48.59% —> 46.89%),但他们的方法可以通过将视频变化理解注入模型来填补这个差距。
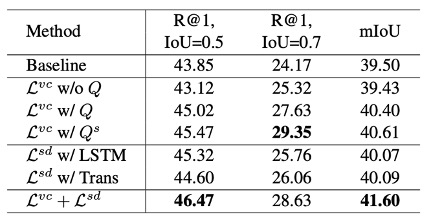
Ablation Study
作者在Charades-STA数据集上进行了实验,并展示了R@1的数据,对于IoU ∈ {0.5, 0.7}和mIoU。使用静态查询来探测视频比使用完整句子和纯视觉上下文生成没有文本的效果更好。这表明避免将视频变化的文本描述与无关的视觉上下文相关联的重要性。
他们还评估了空间动态信息对文本编码器的重要性,研究了两种类型的动态建模,包括LSTM和Transformer Encoder。他们发现,通过引入空间动态信息,无论是LSTM和Transformer Encoder,都能提高VMR的进度。